
Spring源码分析
Spring 源码分析
- Spring 循环依赖
- Spring 生命周期
- Spring AOP
勿以浮沙筑高台
Spring 循环依赖
基础知识
什么是循环依赖
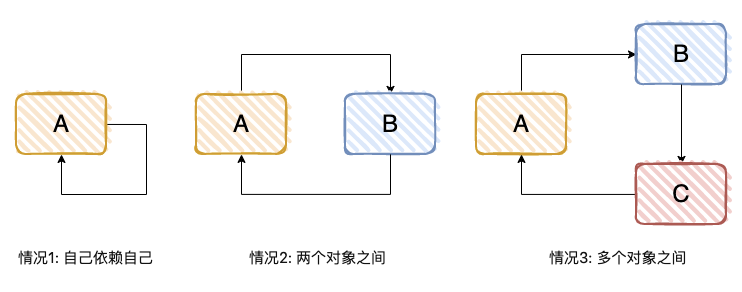
循环依赖指的是一个或多个 bean 之间的依赖关系形成了一个循环,导致 Spring 容器无法完成 bean 的实例化和注入。
三级缓存
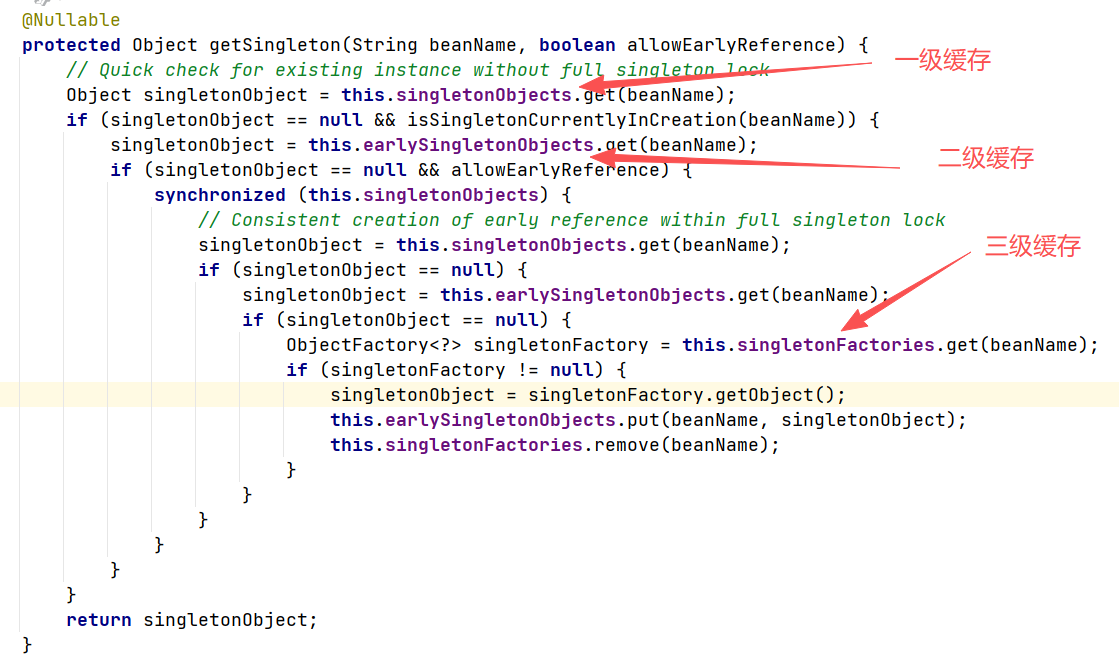
三级缓存是指 Spring 容器在实例化 bean 时使用的缓存机制,用于解决循环依赖问题。三级缓存包含以下几个部分:
- 一级缓存:singletonObjects,⽤于保存实例化、注⼊、初始化完成的 bean。
- 二级缓存:earlySingletonObjects,⽤于保存实例化完成的 bean 实例,即 bean 实例化完成但属性注入未完成的状态。
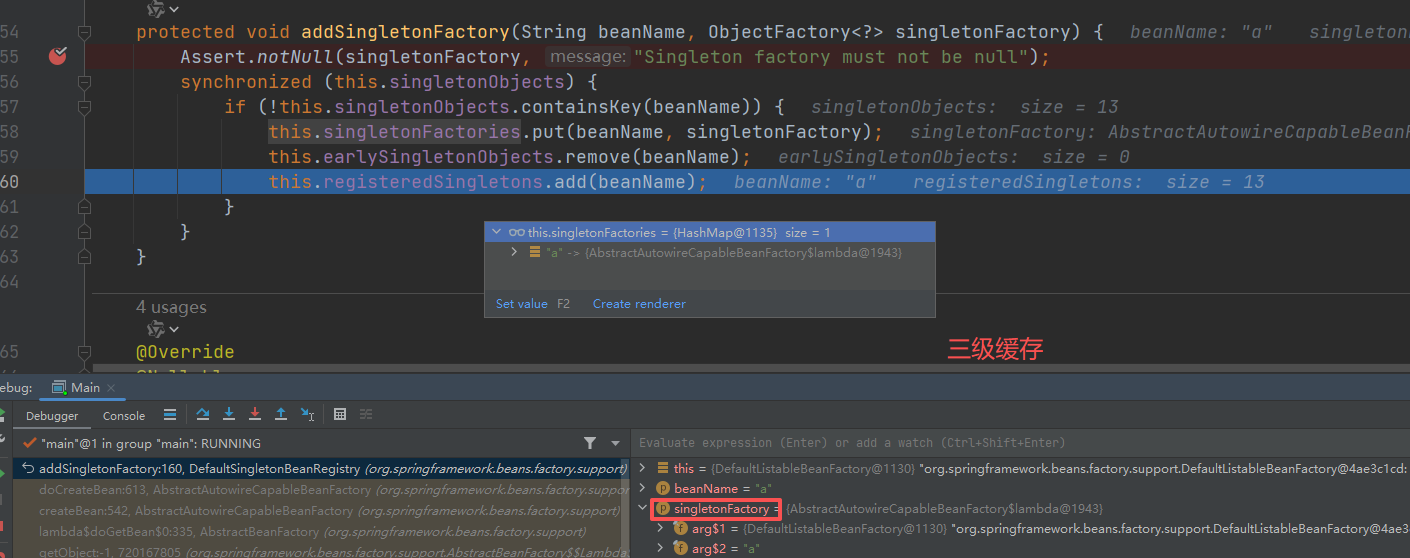
- 三级缓存:singletonFactories,⽤于保存 bean 创建⼯⼚,以便后⾯有机会创建代理对象,即 bean 实例化完成但属性注入未完成的状态。
源码逻辑
- 先从“第⼀级缓存”找对象,有就返回,没有就找“⼆级缓存”;
- 找“⼆级缓存”,有就返回,没有就找“三级缓存”;
- 找“三级缓存”,找到了,就获取对象,放到“⼆级缓存”,从“三级缓存”移除。
执行原理
代码
1 |
|
原理
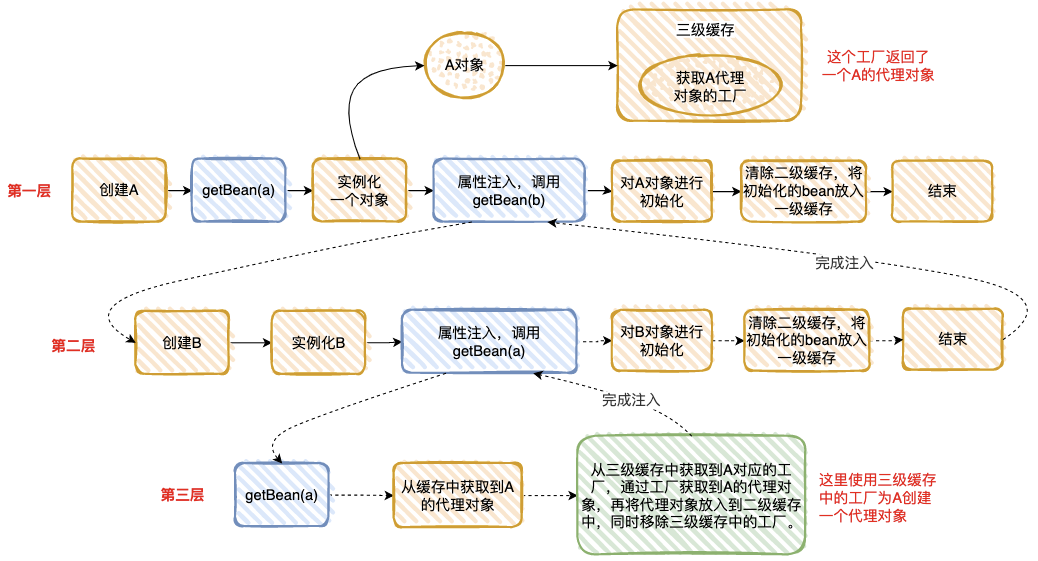
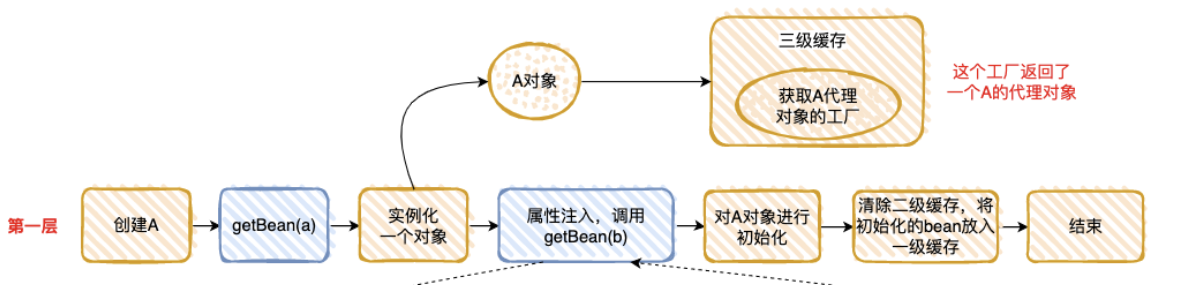
- 在第⼀层中,先去获取 A 的 Bean,发现没有就准备去创建⼀个,然后将 A 的代理⼯⼚放⼊“三级缓存”(这个A 其实是⼀个半成品,还没有对⾥⾯的属性进⾏注⼊),但是 A 依赖 B 的创建,就必须先去创建 B。
- 在第⼆层中,准备创建 B,发现 B ⼜依赖 A,需要先去创建 A。
- 在第三层中,去创建 A,因为第⼀层已经创建了 A 的代理⼯⼚,直接从“三级缓存”中拿到 A 的代理⼯⼚,获取 A 的代理对象,放⼊“⼆级缓存”,并清除“三级缓存”。
- 回到第⼆层,现在有了 A 的代理对象,对 A 的依赖完美解决(这⾥的 A 仍然是个半成品),B 初始化成功。
- 回到第⼀层,现在 B 初始化成功,完成 A 对象的属性注⼊,然后再填充 A 的其它属性,以及 A 的其它步骤(包括 AOP),完成对 A 完整的初始化功能(这⾥的 A 才是完整的 Bean)。
- 将 A 放⼊“⼀级缓存”。
源码解读
入口
1 |
|
第一层
getBean
- AbstractBeanFactory : getBean(String name)
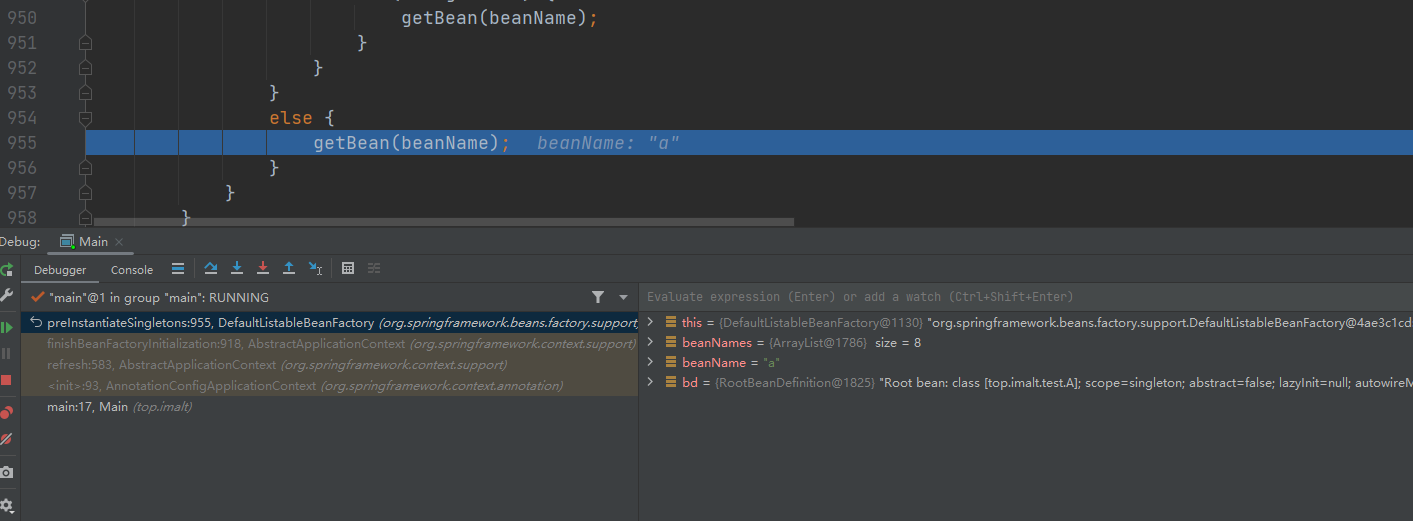
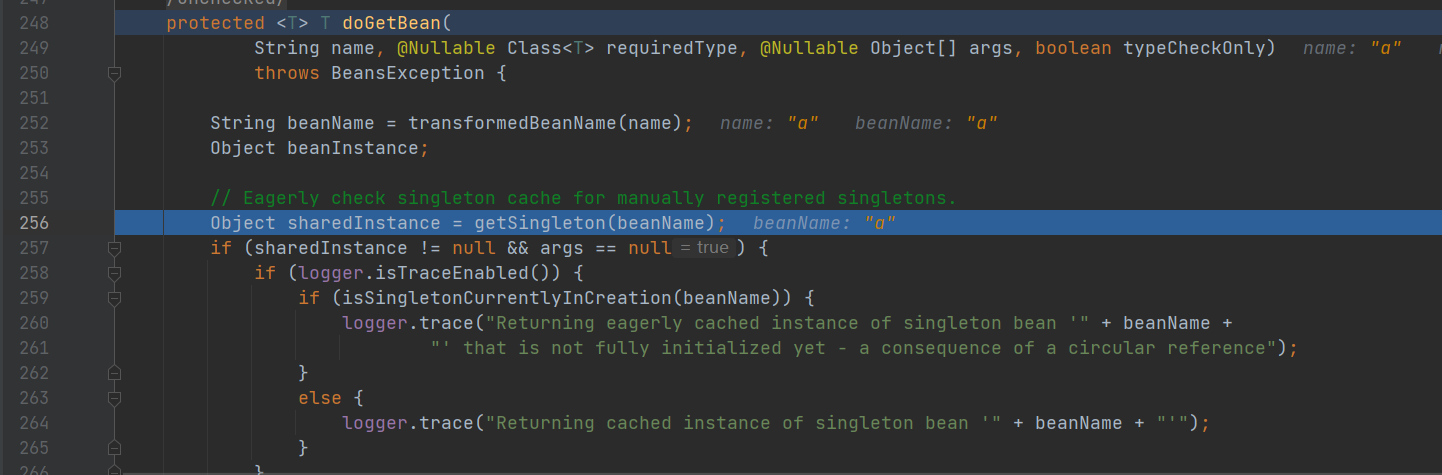
- AbstractBeanFactory : getBean 方法 调用 doGetBean

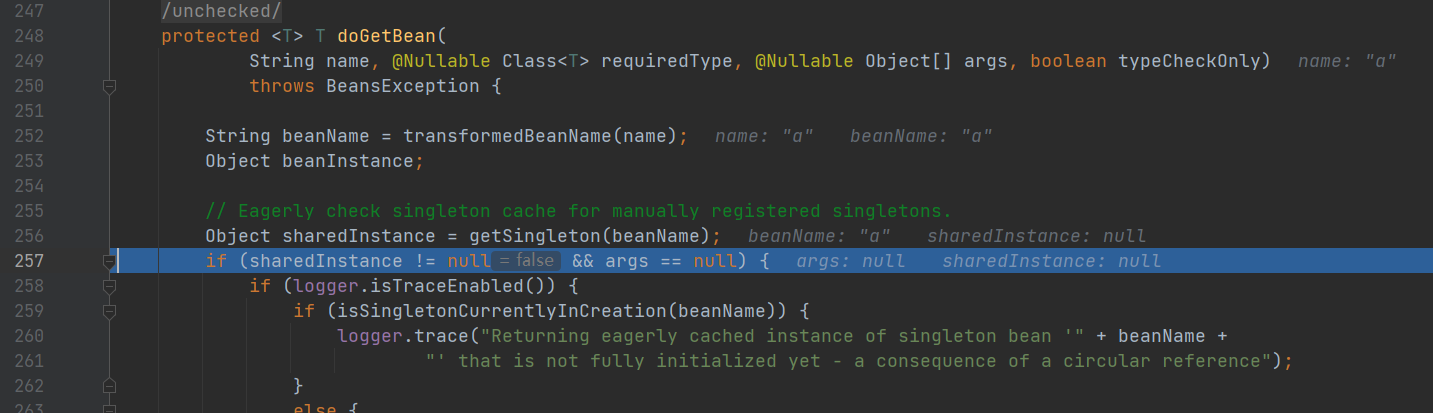
- doGetBean: 从 getSingleton() 没有找到对象
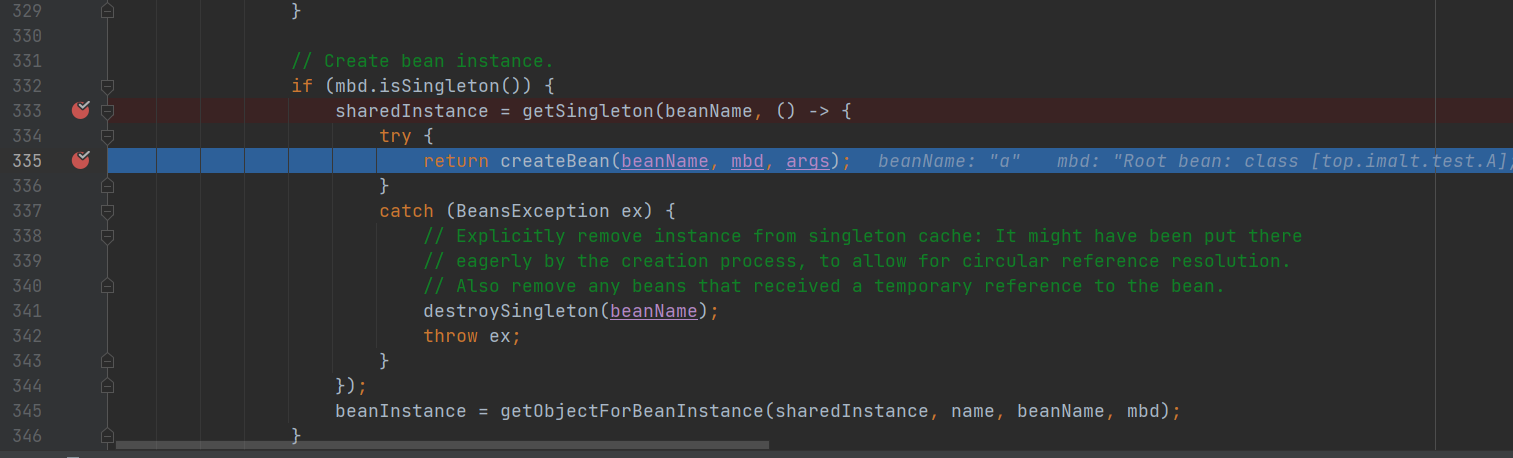
- doGetBean: createBean 创建对象。
- doGetBean: 从 getSingleton() 没有找到对象
实例化对象
- AbstractAutowireCapableBeanFactory: createBean(String beanName, RootBeanDefinition mbd, @Nullable Object[] args)
- Object beanInstance = doCreateBean(beanName, mbdToUse, args)
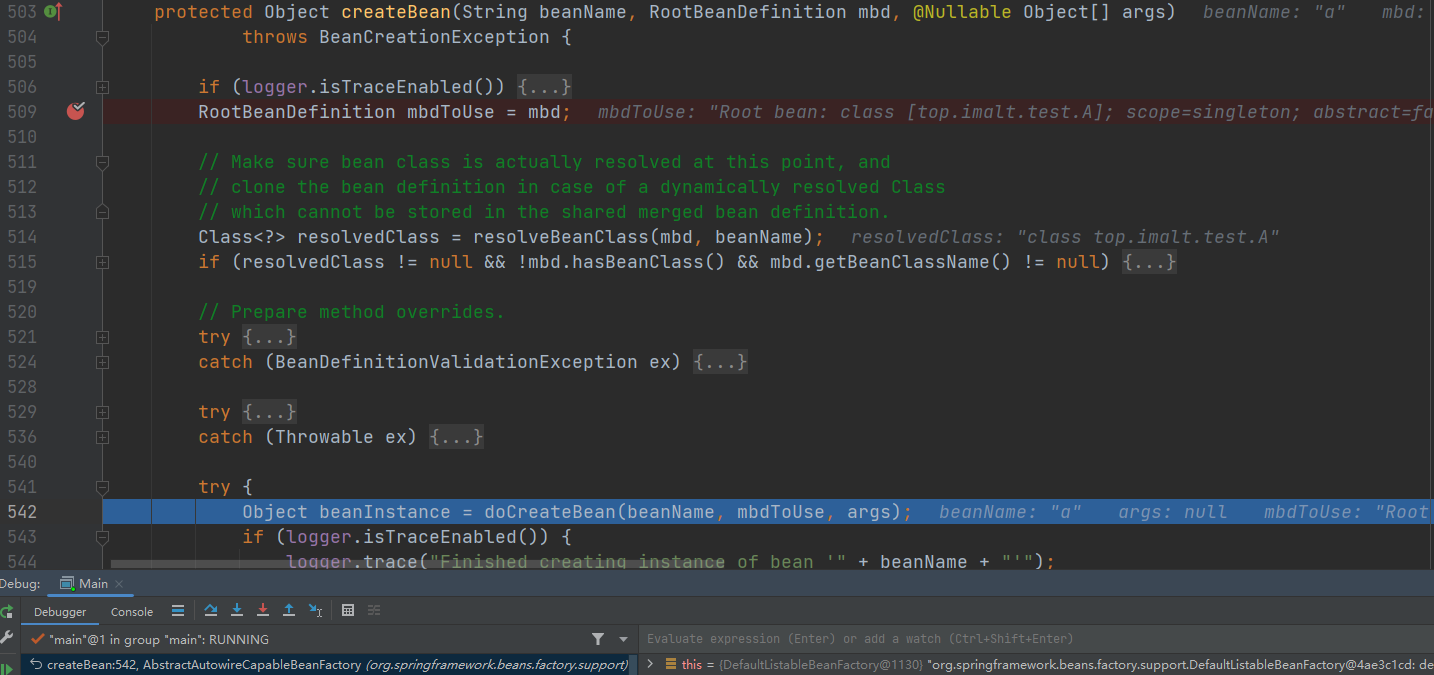
- Object beanInstance = doCreateBean(beanName, mbdToUse, args)
- AbstractAutowireCapableBeanFactory:doCreateBean 方法
- 实例化A对象(属性未赋值): createBeanInstance(beanName, mbd, args);Object bean = instanceWrapper.getWrappedInstance();
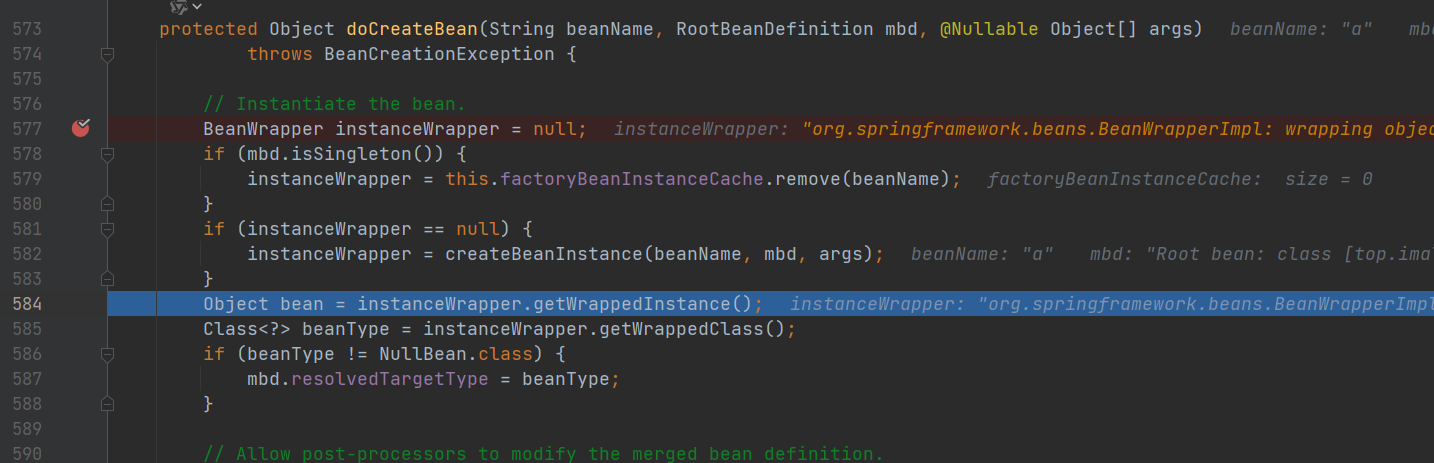
- 将A对象工厂放入三级缓存:addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean))
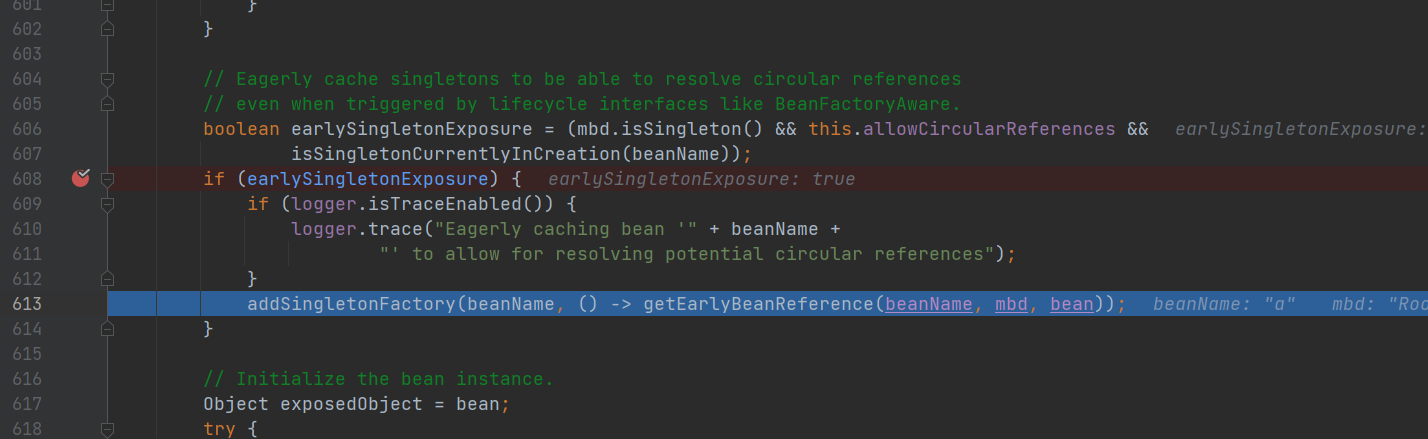
- 对A对象属性赋值:**populateBean(),**包括属性填充、依赖注入、后置处理(BeanPostProcessor等后处理器)
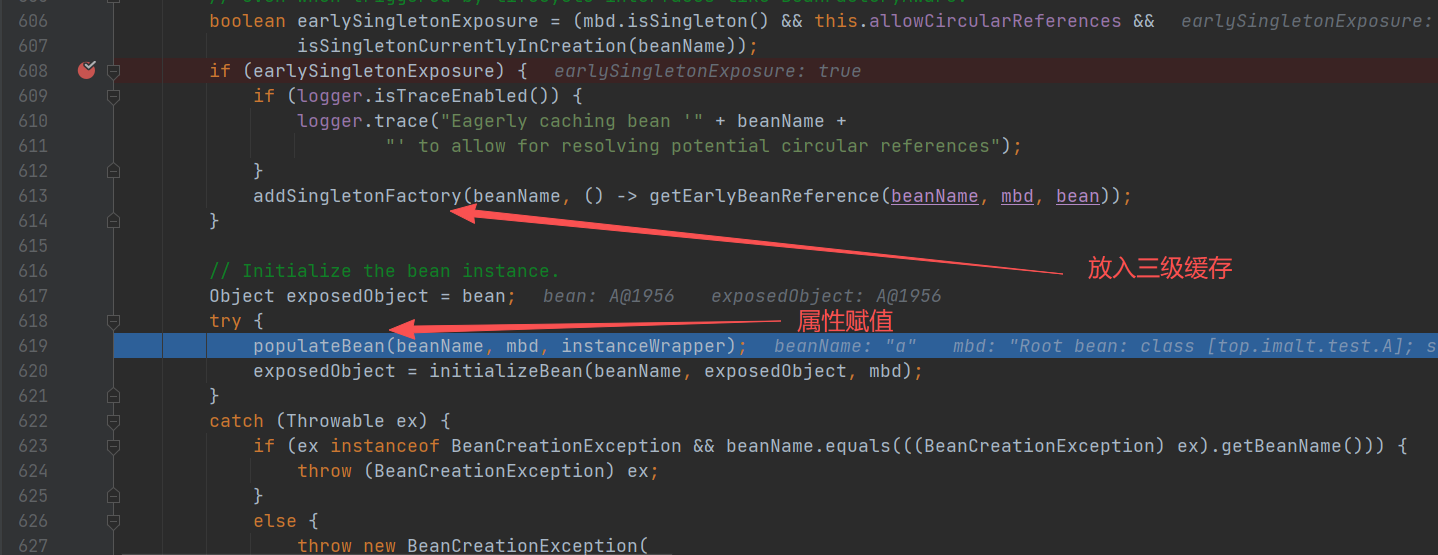
初始化A对象
- AbstractAutowireCapableBeanFactory:populateBean(String beanName, RootBeanDefinition mbd, @Nullable BeanWrapper bw)
- 执行 postProcessProperties() 方法
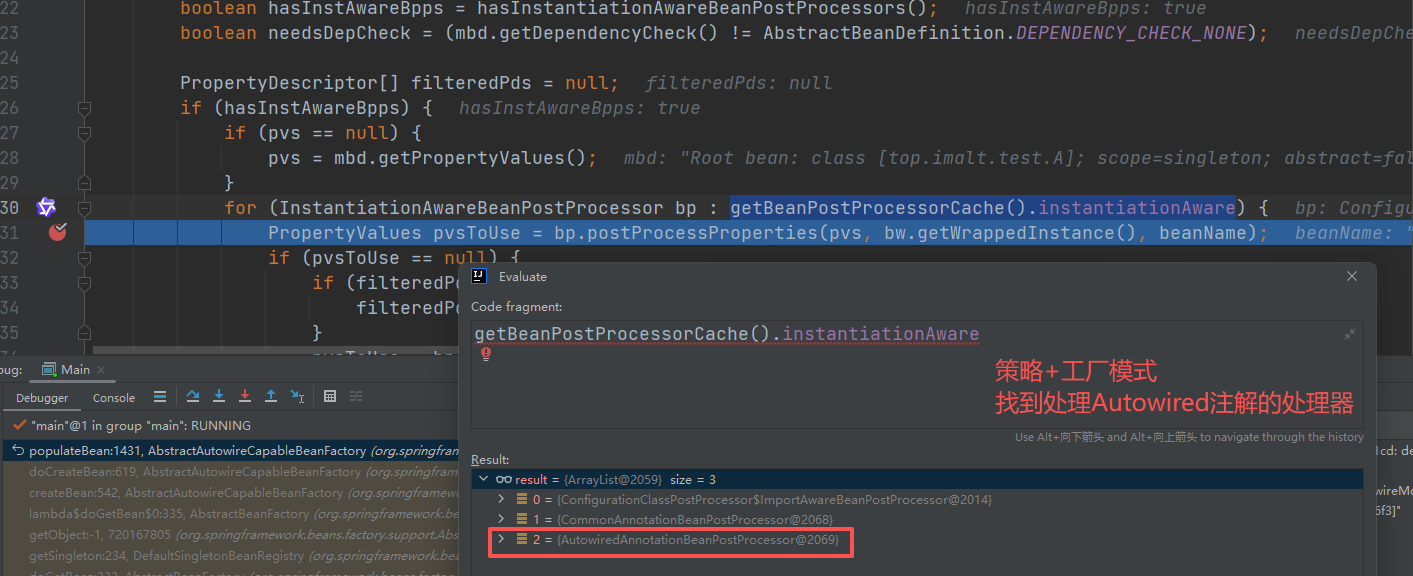
- AutowiredAnnotationBeanPostProcessor 类 处理 ,调用 inject() 方法
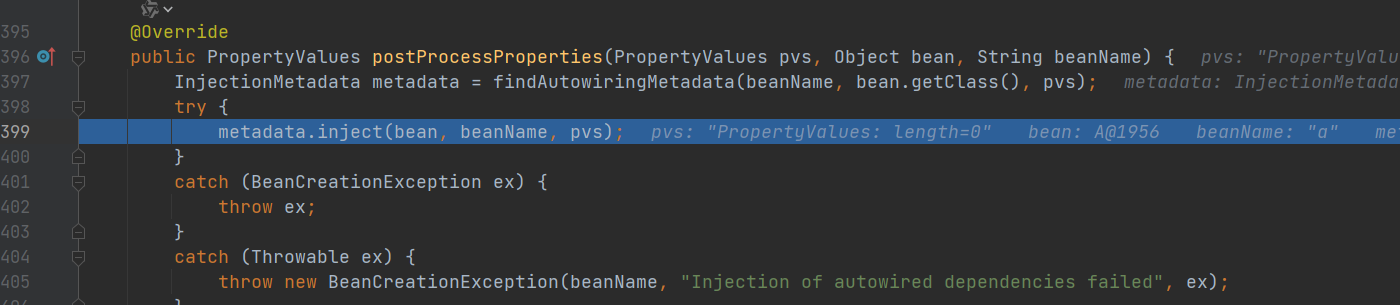
- 需要注入属性b
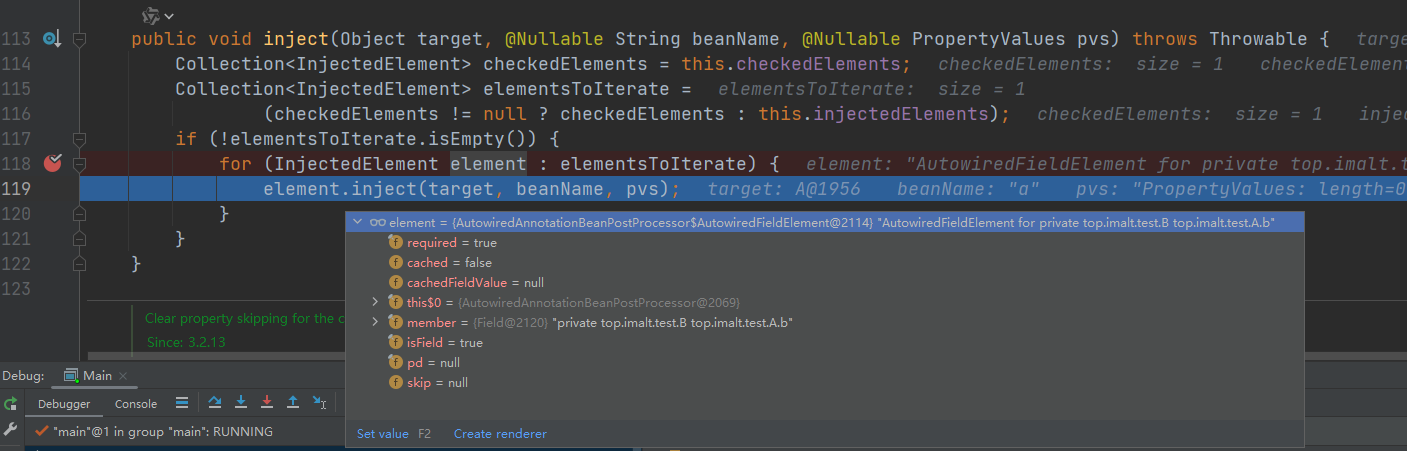
- inject()–> resolveFieldValue(field, bean, beanName)
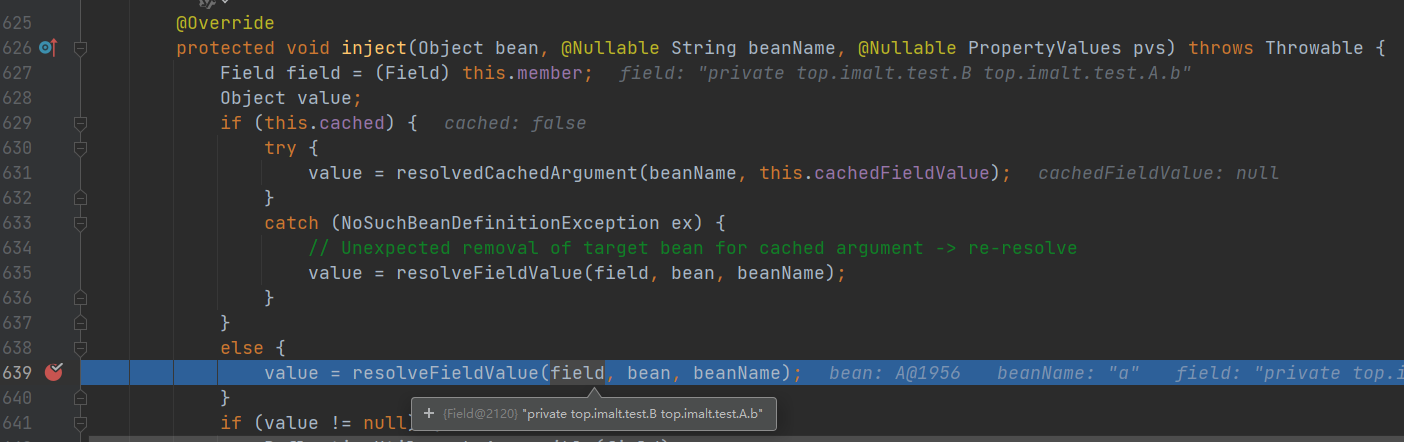
- 交给工厂处理
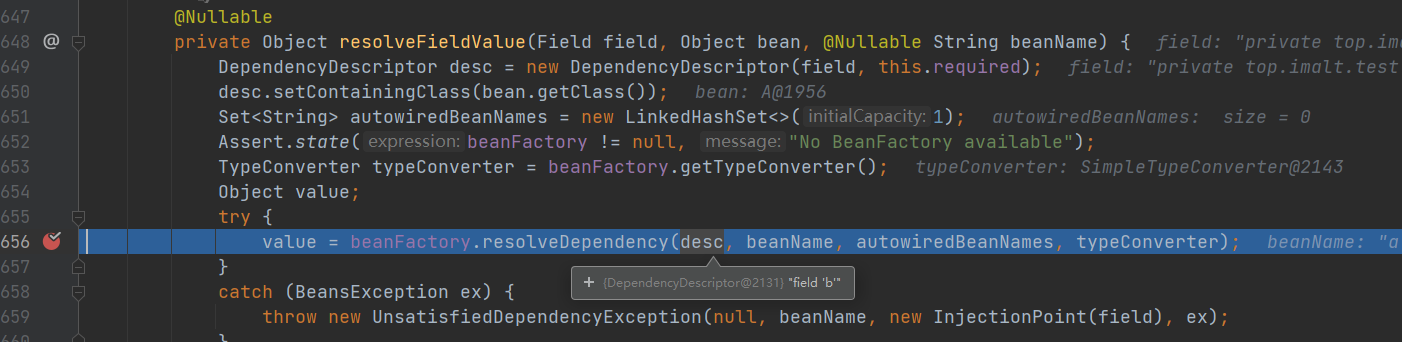
- 调用 doResolveDependency 方法 找到 A 对象依赖属性b
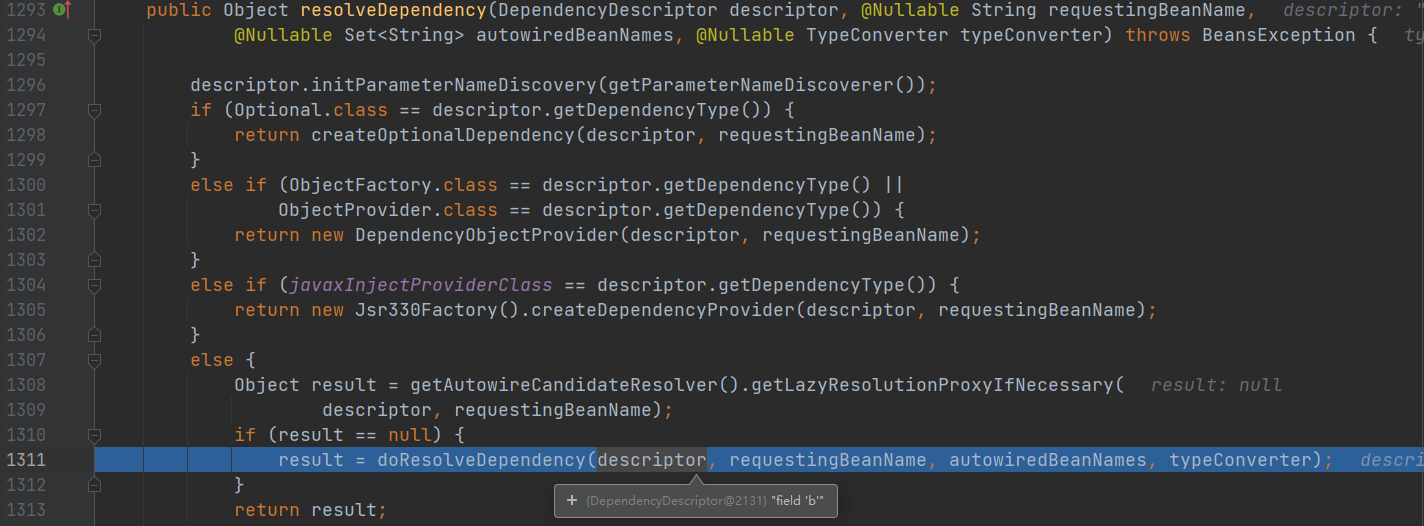
- doResolveDependency() 方法中 ,属性b为class对象, 进行处理
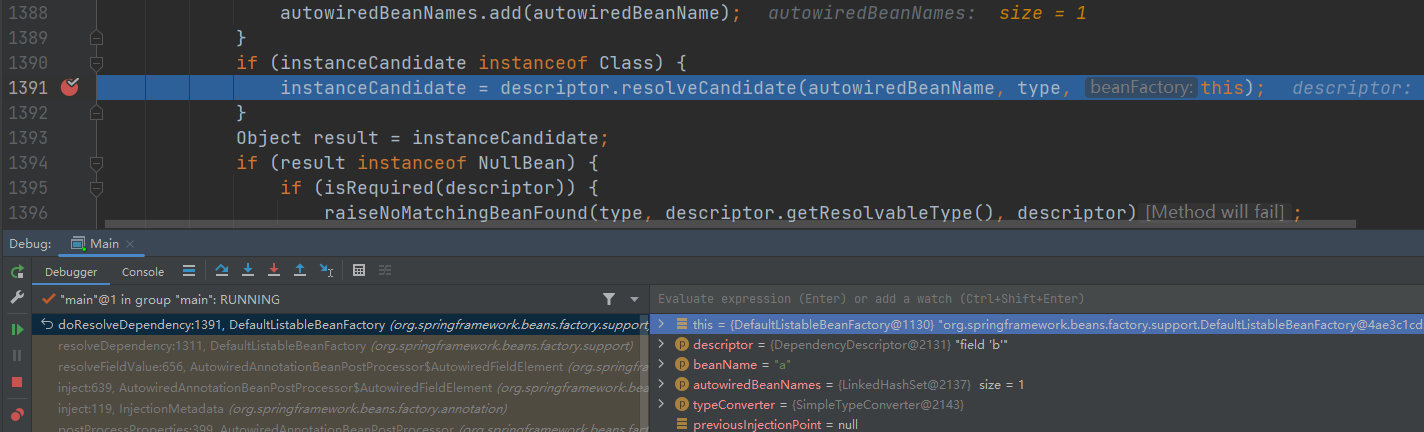
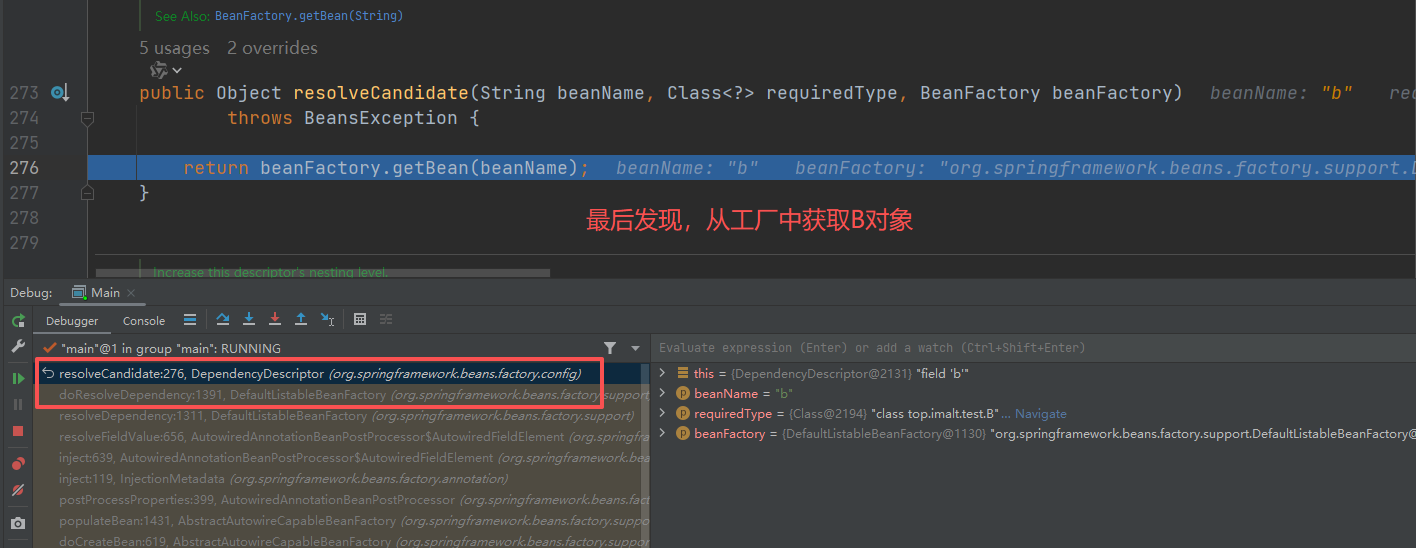
- 再继续进入
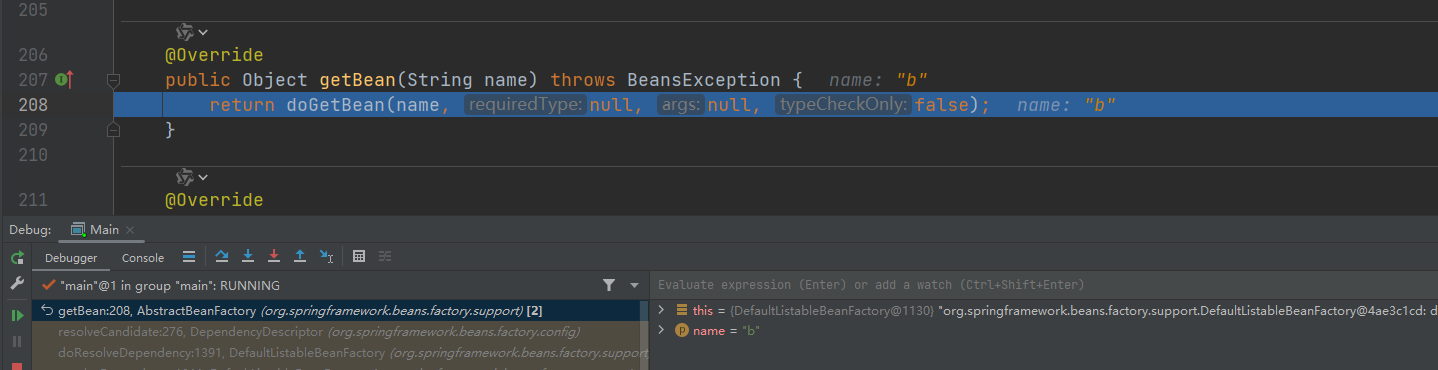
- 第一层结束,B对象,获取,循环进入第二层
第二层

获取 B 的bean,到调用 doGetBean 方法,到populateBean()再到 doResolveDependency() ,逻辑和第一层一样。
- 验证 实例化B 后 放入 三级缓存
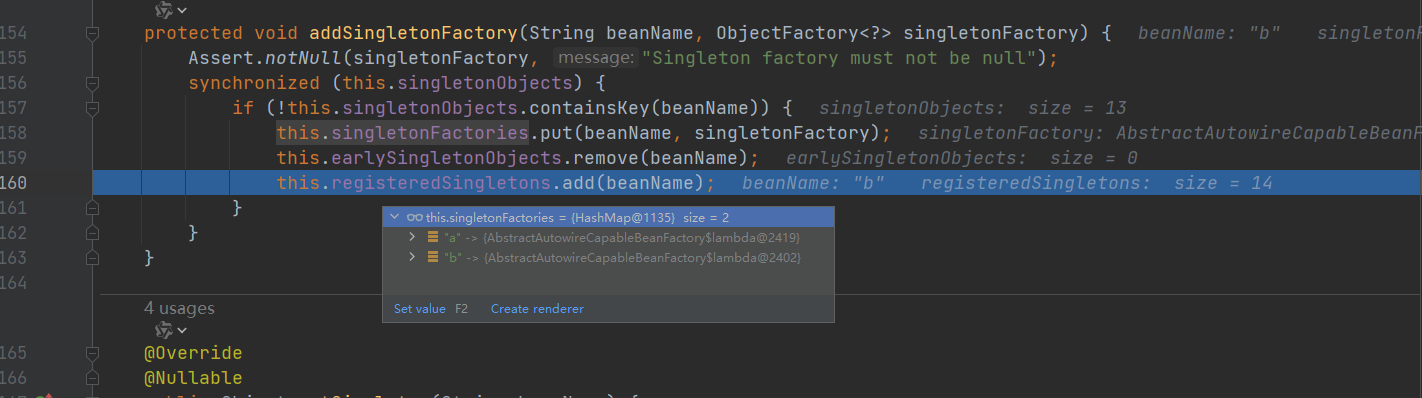
流程省略,直接看B对象 属性注入处理: doResolveDependency() 方法
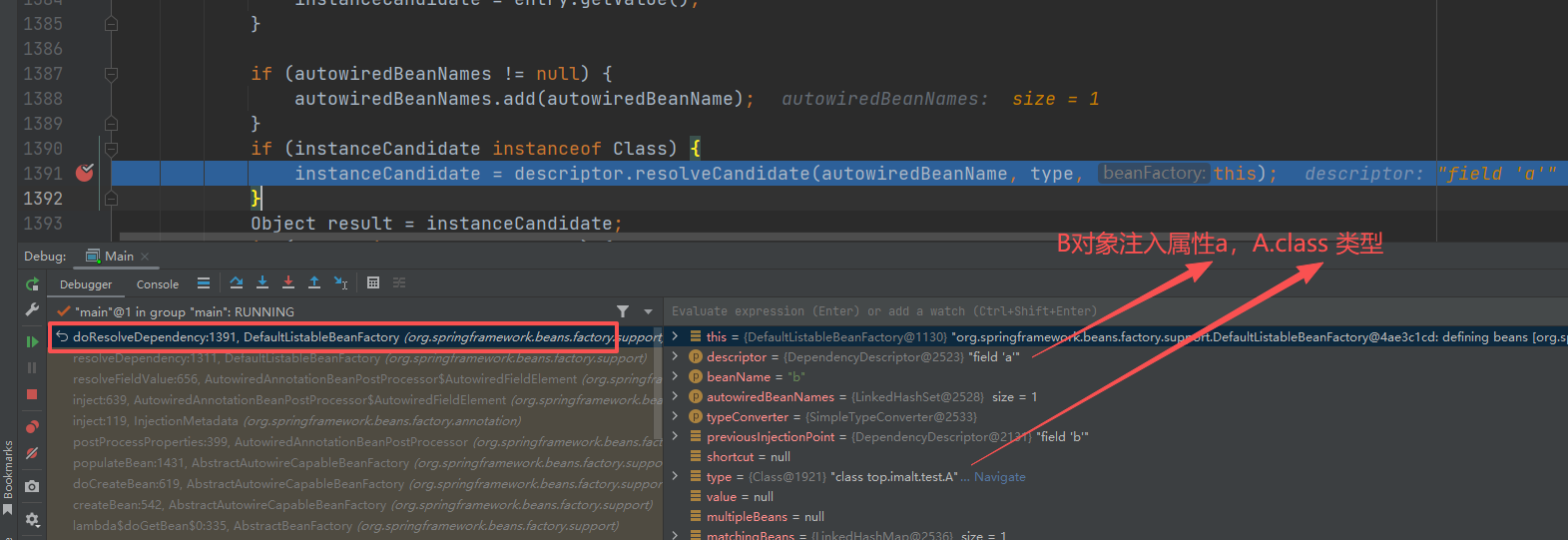
往下执行,发现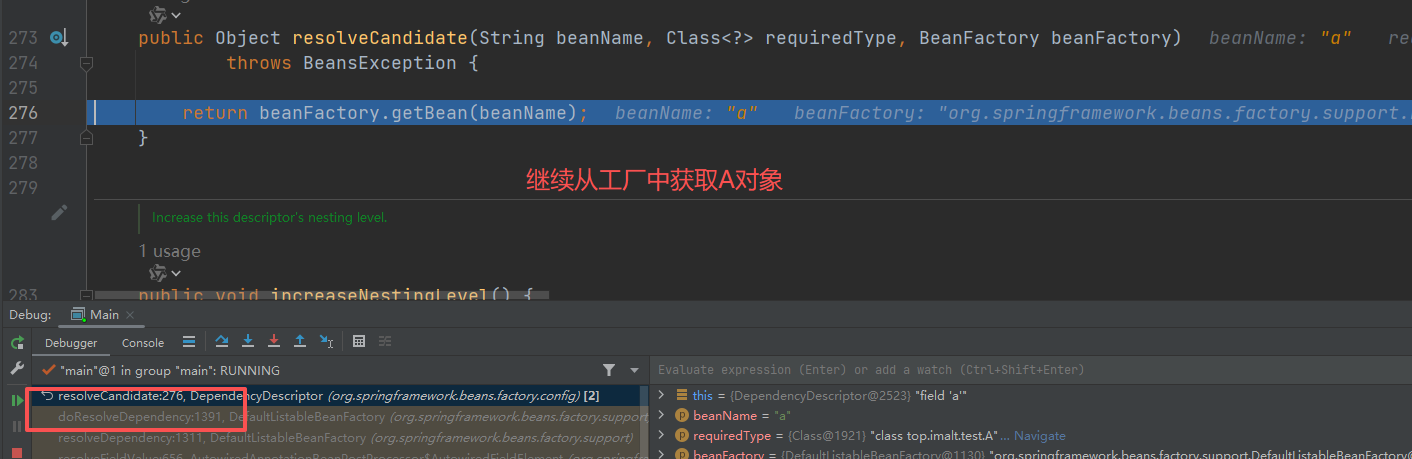
B对象,依赖 A 对象,依旧 从 工厂中获取,这里第二层就是套娃 ,再执行一遍第一层流程
第三层

获取 A 的 bean,在第⼀层和第二层中,我们每次都会从 getSingleton() 获取对象,但是由于之前没有初始
化 A 和 B 的三级缓存,所以获取对象为空。
重点,到了了第三层,由于第三级缓存有A 数据,这⾥使⽤三级缓存中的⼯厂,为 A 创建⼀个代理对象,塞入二级缓存。
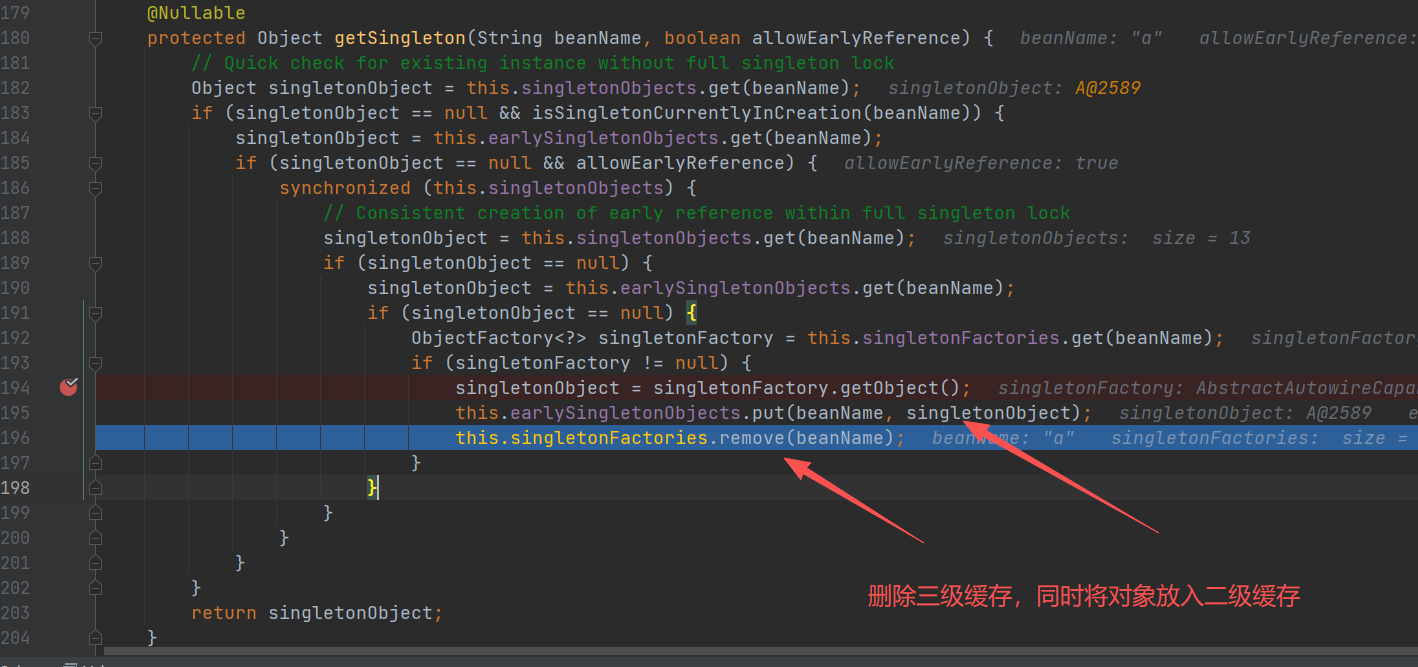
这里拿到A的代理对象,解决了B 的路径依赖关系,返回第二层,并给B对象赋值

返回第二层
返回第⼆层后,B 对象 继续执行 initializeBean() 方法, 初始化结束,这⾥就结束了了么?⼆缓存的数据,啥时候会给到一级呢?
这里:doGetBean() 方法中,我们会通过 createBean() 创建⼀一个 B 的 bean,当B 的
bean 创建成功后,我们会执getSingleton(),它会对 B 的结果进行处理。
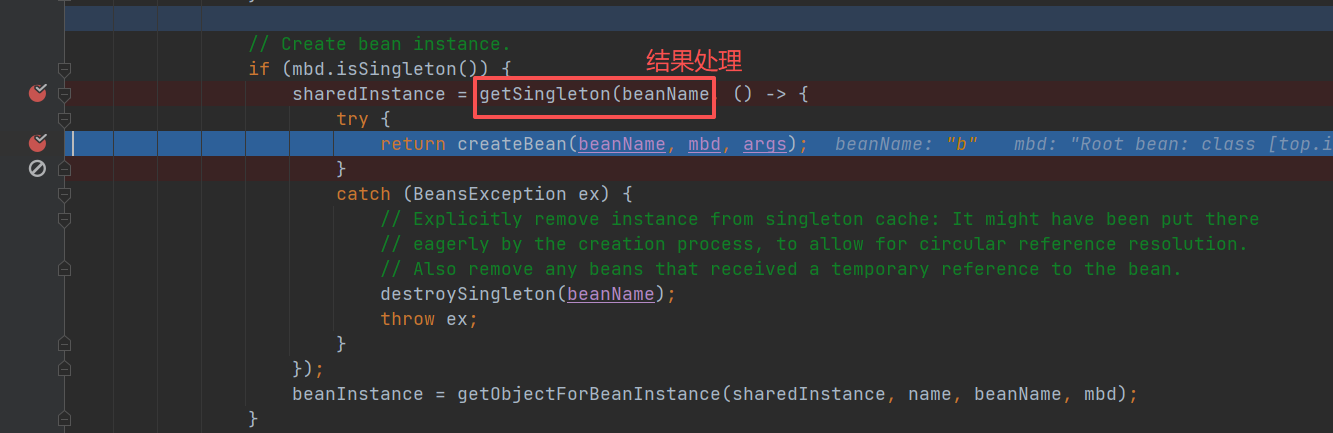
getSingleton()方法中有 addSingleton() 方法
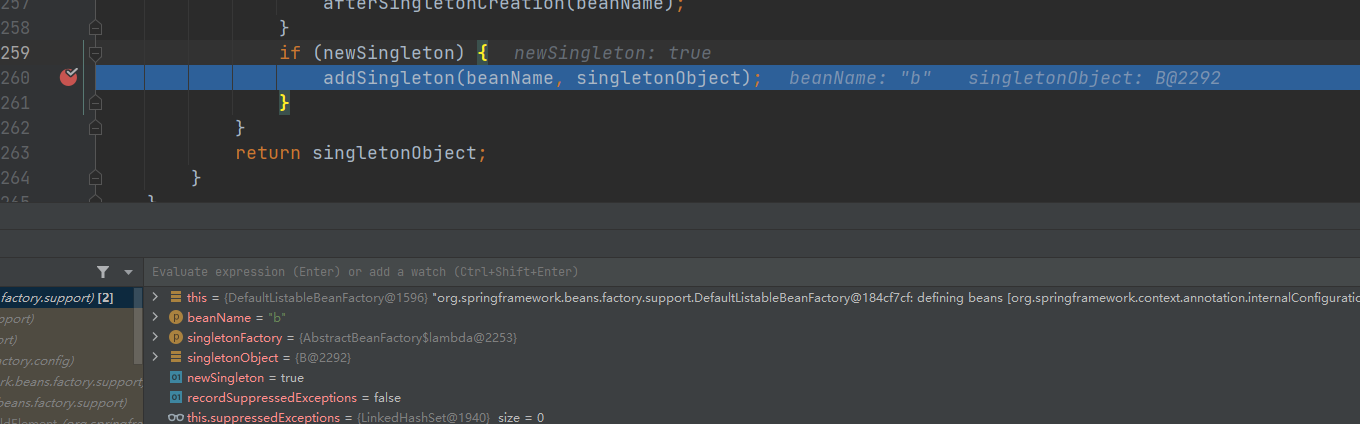
addSingleton() 方法 详细处理
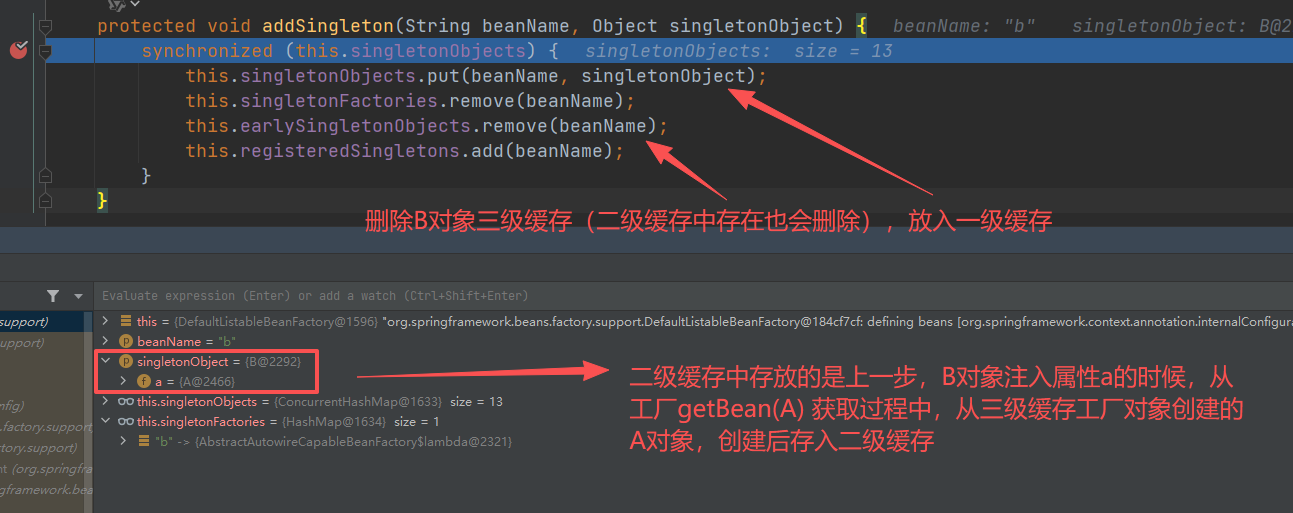
getSingleton()方法结束后,已经创建好B 对象,并返回。
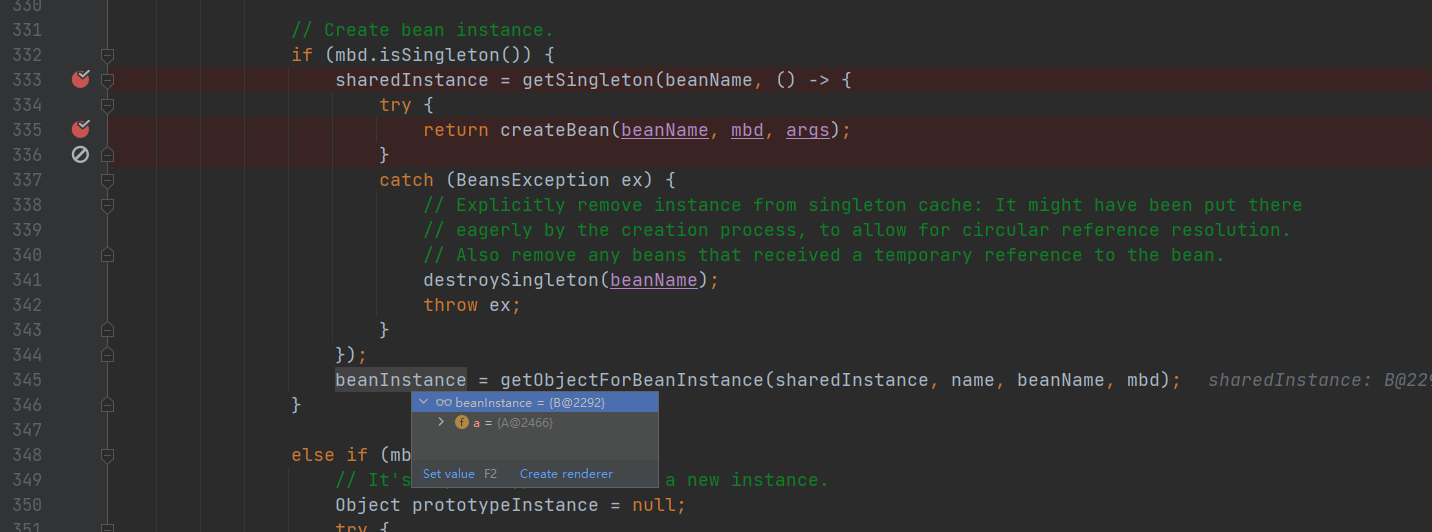
返回一层
注意此时B对象初始化也完成了,返回B对象, 此时A对象正在进行对b属性赋值。
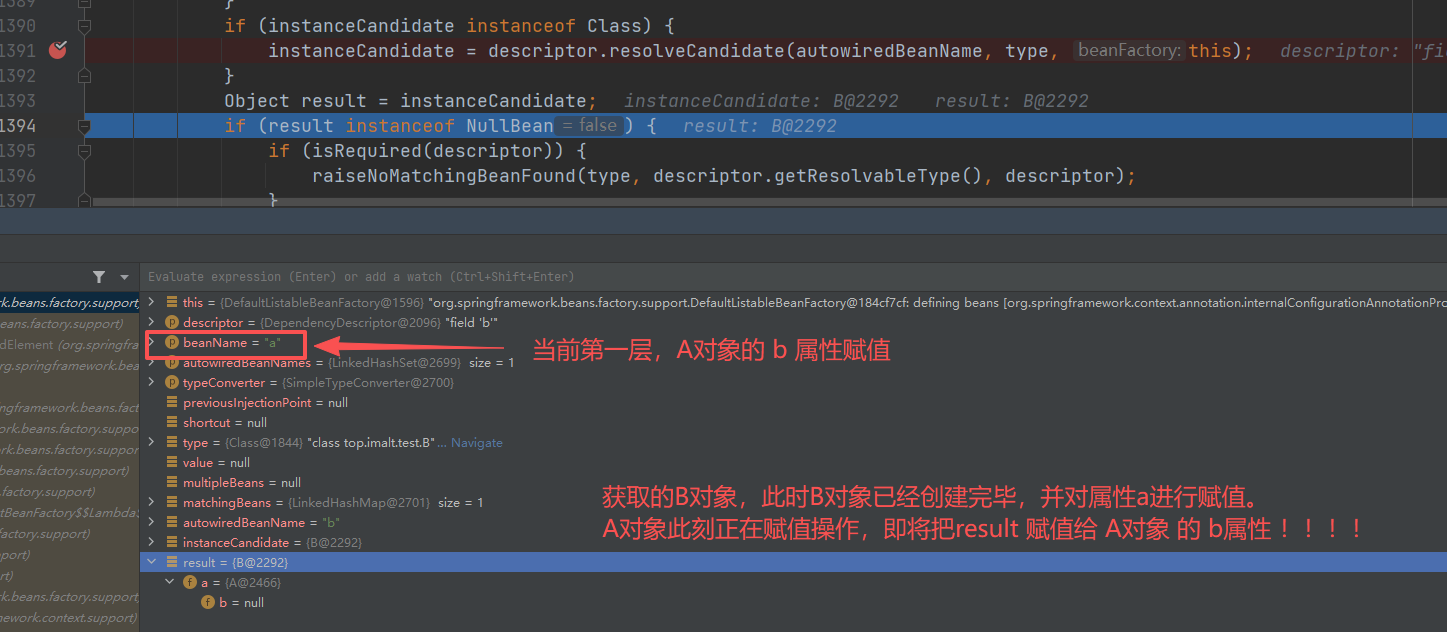
resolveFieldValue() 拿到具体的b属性值,并赋值给A对象
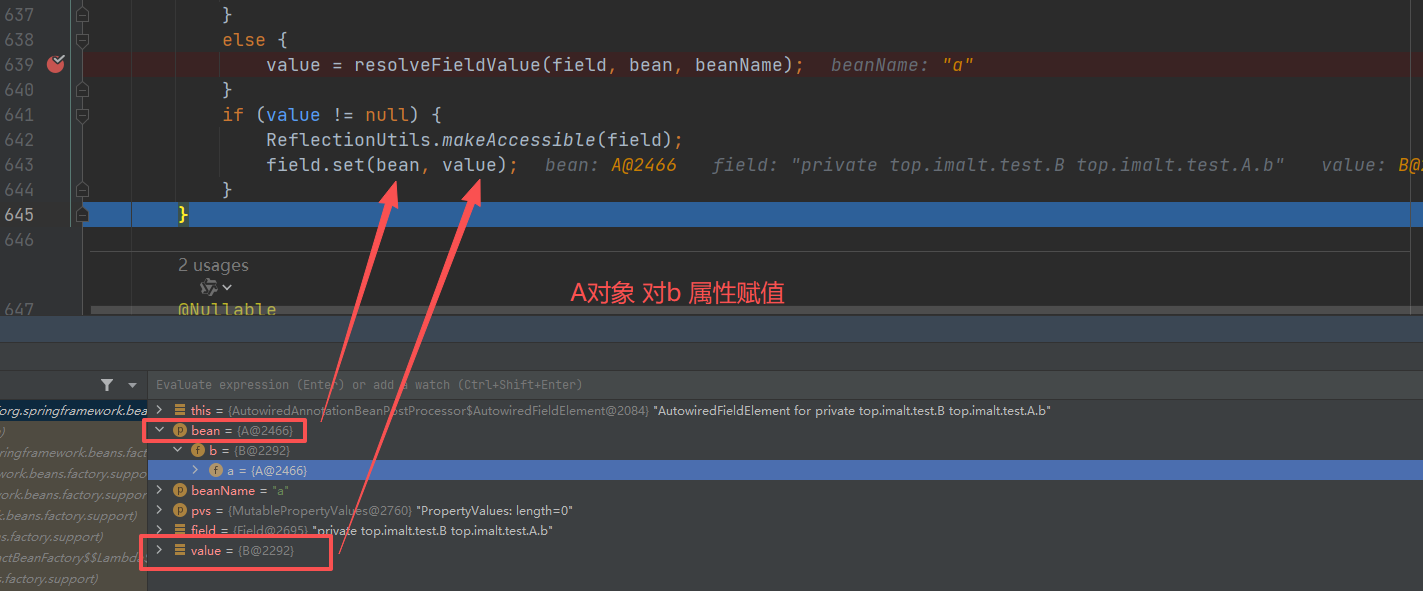
原理解读
为什么要3级缓存
这是一道非常经典的面试题,前面详细的执行流程,包括源码解读,没有提到为什么要用 3级缓存?
这里是重点!
我们先说“一级缓存”的作用,变量命名为 singletonObjects,结构是 Map<String,Object>,它就是一个单例池将初始化好的对象放到里面,给其它线程使用,如果没有第一级缓存,程序不能保证Spring 的单例属性。
“二级缓存”先放放,我们直接看”三级缓存”的作用,变量命名为 singletonFactories,结构是 Map<String,ObjectFactory<?>>,Map 的 Value 是一个对象的代理工厂,所以“三级缓存”的作用,其实就是用来存放对象的代理工厂。
那这个对象的代理工厂有什么作用呢,它的主要作用是存放半成品的单例 Bean,目的是为了“打破循环”:
我们回到文章开头的例子,创建A对象时,会把实例化的 A对象存入”三级缓存”,这个A其实是个半成品,因为没有完成依赖属性 B的注入,所以后面当初始化 B时,B 又要去找 A,这时就需要从”三级缓存”中拿到这个半成品的A(这里描述,其实也不完全准确,因为不是直接拿,为了让大家好理解,我就先这样描述),打破循环。
那为什么“三级缓存”不直接存半成品的 A,而是要存一个代理工厂呢?答案是因为 AOP。
在解释这个问题前,我们看一下这个代理工厂的源码,让大家有一个更清晰的认识。
直接找到创建 A对象时,把实例化的 A对象存入“三级缓存”的代码,直接用前面的两幅截图。
- getEarlyBeanReference(beanName, mbd, bean))
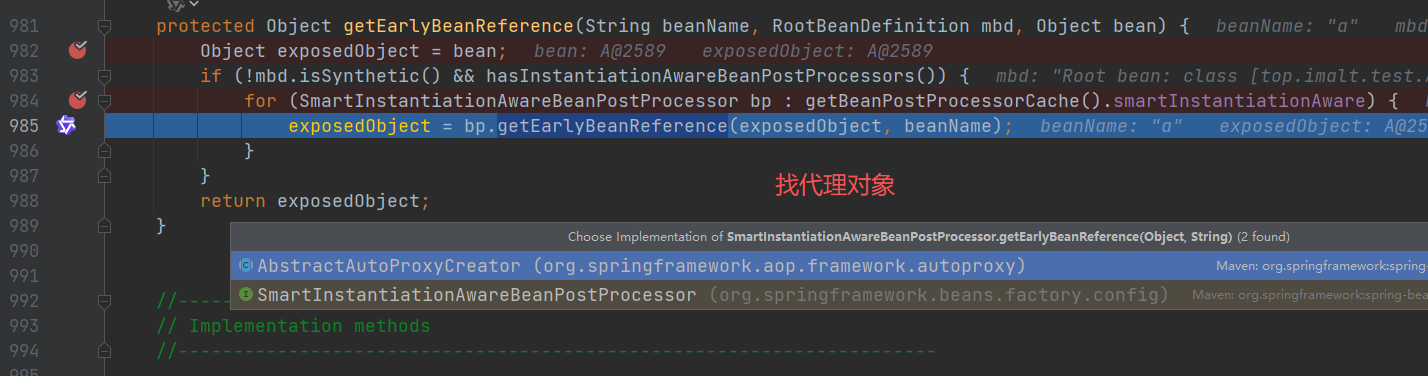

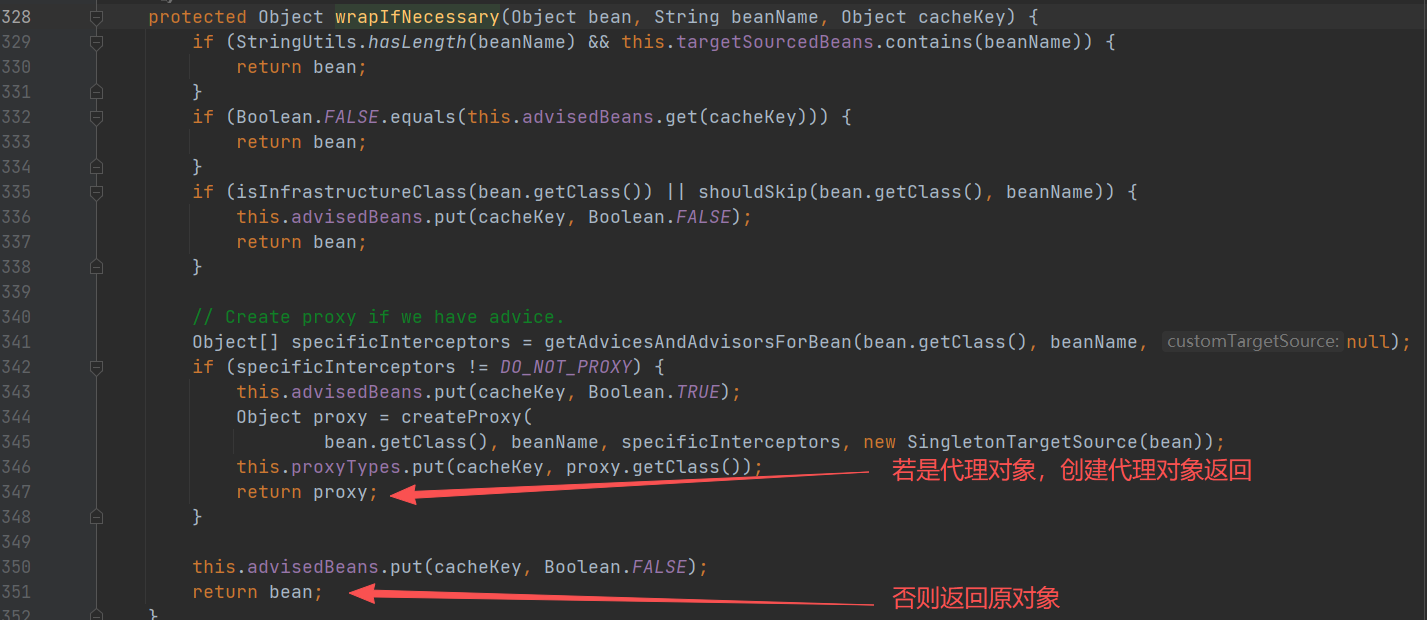
最后一张图最总要
- 如果 A 有 AOP,就创建⼀一个代理理对象
- 如果 A 没有 AOP,就返回原对象
那“三级缓存”的作用就清楚了: 就是用来存放对象工厂生成的对象,这个对象可能是原对象,也可能是个代理对。
能干掉二级缓存么?
1 |
|
根据上面的套娃逻辑,A 需要找 B 和 C,但是B需要找 A,C也需要找 A。
假如 A 需要进行 AOP,因为代理对象每次都是生成不同的对象,如果干掉第二级缓存,只有第一、三级缓存:
B 找到 A时,直接通过三级缓存的工厂的代理对象,生成对象 A1。
C找到 A时,直接通过三级缓存的工厂的代理对象,生成对象 A2。
看到问题没?你通过A的工厂的代理对象,生成了两个不同的对象 A1和 A2,所以为了避免这种问题的出现,我们搞个二级缓存,把 A1 存下来,下次再获取时,直接从二级缓存获取,无需再生成新的代理对象。
所以“二级缓存”的目的是为了避免因为 AOP 创建多个对象,其中存储的是半成品的 AOP 的单例 bean。
如果没有 AOP 的话,我们其实只要 1、3 级缓存,就可以满足要求。
总结
3 级缓存的作⽤:
一级缓存:为“’Spring的单例属性”而生,就是个单例池,用来存放已经初始化完成的单例 Bean;
二级缓存:为“解决 AOP”而生,存放的是半成品的 AOP 的单例 Bean;
三级缓存:为“打破循环”而生,存放的是生成半成品单例 Bean 的工厂方法。
Spring 生命周期
基础知识
什么是IOC?
1oC,控制反转,所谓的控制反转,就是把 new 对象的权利交给容器,所有的对象都被容器控制,这就叫所谓的控制反转。
loC很好地体现了面向对象设计法则之- – 好菜坞法则:“别找我们,我们找你“,即由loC 容器帮对象找相应的依赖对象并注入,而不是由对象主动去找。
理解好 lOC的关键是要明确“谁控制谁,控制什么,为何是反转(有反转就应该有正转了),哪些方面反转了”。
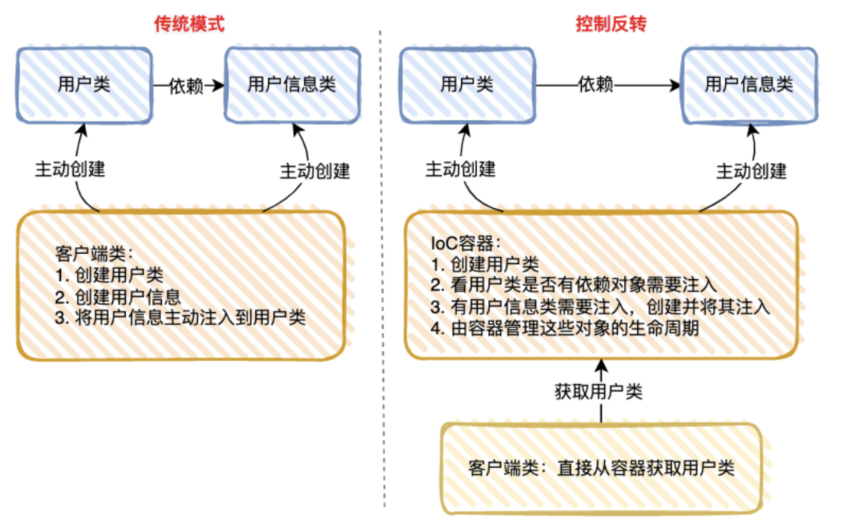
谁控制谁,控制什什么?
传统 Java SE 程序设计,我们直接在对象内部通过 new 进⾏行行创建对象,是程序主动去创建依赖对象。⽽而 IoC 是由专
⻔⼀个容器来创建这些对象,即由 IoC 容器来控制对象的创建。
- 谁控制谁?当然是 IoC 容器器控制了了对象。
- 控制什么?主要控制了了外部资源获取(不只是对象,⽐比如包括⽂文件等)。
为何是反转,哪些⽅方面反转了?
有反转就有正转,传统应⽤用程序是由我们⾃己在对象中主动控制去直接获取依赖对象,也就是正转,⽽而反转则是由
容器来帮忙创建及注入依赖对象。
- 为何是反转?因为由容器帮我们查找及注⼊入依赖对象,对象只是被动的接受依赖对象,所以是反转。
- 哪些⽅方⾯反转了了?依赖对象的获取被反转了。
Bean 的生命周期
对 Prototype Bean 来说,当⽤用户 getBean 获得 Prototype Bean 的实例例后,IOC 容器就不再对当前实例进行管
理,而是把管理权交由⽤用户,此后再 getBean ⽣成的是新的实例。
所以我们描述 Bean 的⽣生命周期,都是指的 Singleton Bean。
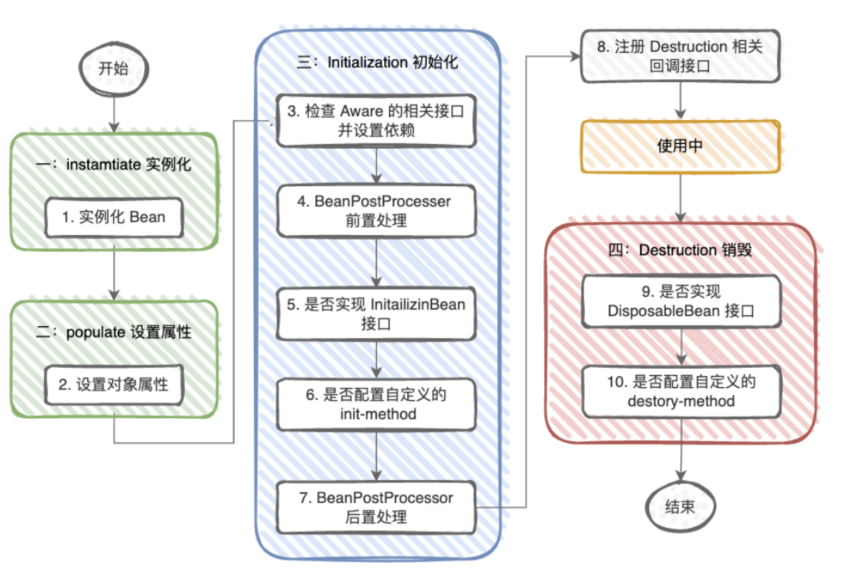
Spring 装配Bean
入口:AbstractAutowireCapableBeanFactory:doCreateBean( )方法
1.实例化Bean:createBeanInstance() ,优先级顺序:Supplier > 工厂方法 > 缓存构造函数 > 构造函数自动装配 > 首选构造函数 > 无参构造函数
1.确保bean类在此时实际上已被解析:resolveBeanClass(mbd, beanName);
2.处理Supplier回调 : obtainFromSupplier(instanceSupplier, beanName);
3.处理工厂方法:instantiateUsingFactoryMethod(beanName, mbd, args);
4.处理缓存构造函数
- 检查 args 为 null,检查 RootBeanDefinition.resolvedConstructorOrFactoryMethod 缓存
- 存在缓存,调用autowireConstructor(beanName, mbd, null, null);
- 不存在缓存,调用instantiateBean(beanName, mbd);
- 检查 args 为 null,检查 RootBeanDefinition.resolvedConstructorOrFactoryMethod 缓存
5.构造函数自动装配:获取候选构造函数 determineConstructorsFromBeanPostProcessors(beanClass, beanName)
- 满足:以下任意之一
- 存在候选构造函数
- 自动装配模式为 AUTOWIRE_CONSTRUCTOR
- RootBeanDefinition 包含构造函数参数值
- 提供了显式的构造函数参数 args
- 调用:autowireConstructor(beanName, mbd, ctors, args)
- 满足:以下任意之一
6.首选构造函数:getPreferredConstructors()
- 不为空,autowireConstructor(beanName, mbd, ctors, null)
7.处理无参构造函数:instantiateBean(beanName, mbd)
2.设置属性值:populateBean()
- 1.实例化后置处理
- 处理 InstantiationAwareBeanPostProcessor 所有接口,调用 postProcessAfterInstantiation 方法 允许后处理器在设置属性前修改 bean 状态,如果任一后处理器返回 false,则提前返回
- 2.Autowire自动装配处理
- 获取 RootBeanDefinition.getResolvedAutowireMode() 确定自动装配模式:
- 弄清楚是应用setter自动装配还是构造函数自动装配,如果它有一个无参数的构造函数,它被认为是setter自动生成的,否则,将尝试构造函数自动装配
- 按名称自动装配 (AUTOWIRE_BY_NAME):调用 autowireByName 方法
- 按类型自动装配 (AUTOWIRE_BY_TYPE):调用 autowireByType 方法
- 获取 RootBeanDefinition.getResolvedAutowireMode() 确定自动装配模式:
- 3.后处理器属性处理
- 处理 InstantiationAwareBeanPostProcessor 所有接口,调用 postProcessProperties 方法 处理属性值
- 4.设置属性值:调用 applyPropertyValues 方法将最终的属性值应用到 bean 实例
- 1.实例化后置处理
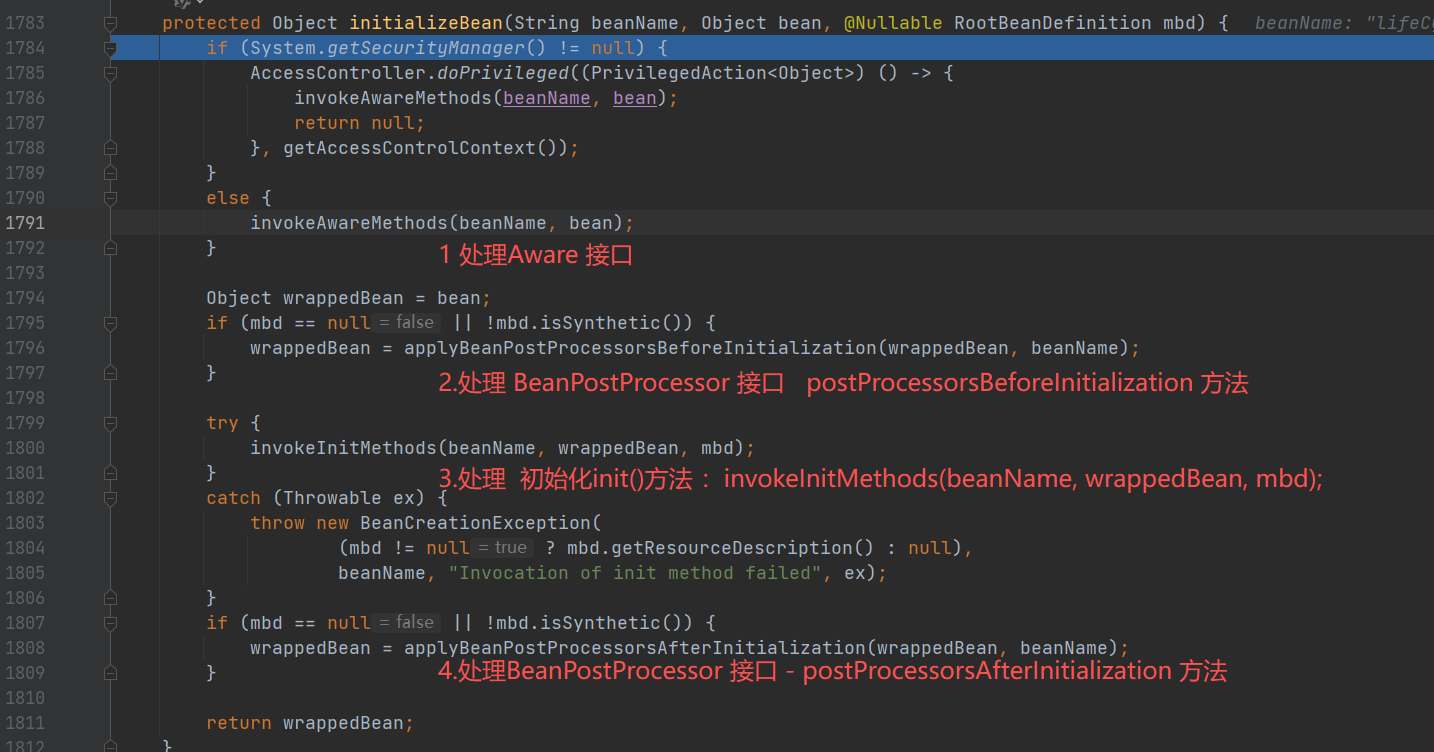
初始化:initializeBean():
- 3.核心 一 处理Aware 相关接口:invokeAwareMethods(beanName, bean);
- 1.处理BeanNameAware接口,调用 setBeanName 设置 Bean 的 ID 或者 Name
- 2.处理BeanClassLoaderAware接口,调用 setBeanFactory 设置 BeanFactory
- 3.处理BeanFactoryAware接口,调用 setApplicationContext 设置 ApplicationContext
- 4.核心 二 处理 BeanPostProcessor 接口 前置处理- postProcessorsBeforeInitialization 方法: applyBeanPostProcessorsBeforeInitialization(wrappedBean, beanName)
- 框架内置:ApplicationContextAwareProcessor,处理指定接Aware接口:EnvironmentAware、EmbeddedValueResolverAware、ResourceLoaderAware、ApplicationEventPublisherAware、MessageSourceAware、ApplicationContextAware、ApplicationStartupAware
- 核心 三 处理 初始化方法 :invokeInitMethods(beanName, wrappedBean, mbd);
- 5.处理 InitializingBean 接口
- 6.处理 执行自定义的初始化方法 init-method
- 7**.核心 四 处理 BeanPostProcessor 接口 后置处理**- postProcessorsAfterInitialization 方法:applyBeanPostProcessorsAfterInitialization(wrappedBean, beanName);
- 3.核心 一 处理Aware 相关接口:invokeAwareMethods(beanName, bean);
Spring 销毁Bean
- 1.处理BeanPostProcessor 子接口 DestructionAwareBeanPostProcessor 接口: processor.postProcessBeforeDestruction(this.bean, this.beanName)
- 2.处理DisposableBean接口: ((DisposableBean) this.bean).destroy()
- 3.处理AutoCloseable接口: ((AutoCloseable) this.bean).close()
- 4.处理自定义的销毁方法 destroy-method: invokeCustomDestroyMethod(this.destroyMethod)
执行流程
1 | public class LifeCycleBean implements InitializingBean, BeanFactoryAware, BeanNameAware, |
1 | public class LifeCycleBeanPostProcessor implements BeanPostProcessor { |
1 |
|
执行结果:
1 | 1. 构造方法进入 |
扩展方法
我们发现,整个⽣生命周期有很多扩展过程,⼤大致可以分为 4 类:
Aware 接⼝:让 Bean 能拿到容器的⼀一些资源,例如 BeanNameAware 的 setBeanName(),
BeanFactoryAware 的 setBeanFactory()
后处理器:进⾏一些前置和后置的处理,例如 BeanPostProcessor 的 postProcessBeforeInitialization()
和 postProcessAfterInitialization()⽣命周期接口:定义初始化⽅方法和销毁⽅方法的,例如 InitializingBean 的 afterPropertiesSet(),以及DisposableBean 的 destroy();
配置⽣生命周期⽅方法:可以通过配置⽂文件,⾃自定义初始化和销毁⽅方法,例例如配置⽂文件配置的 init() 和destroyMethod()。
源码解读
代码入口
1 | public class Main { |
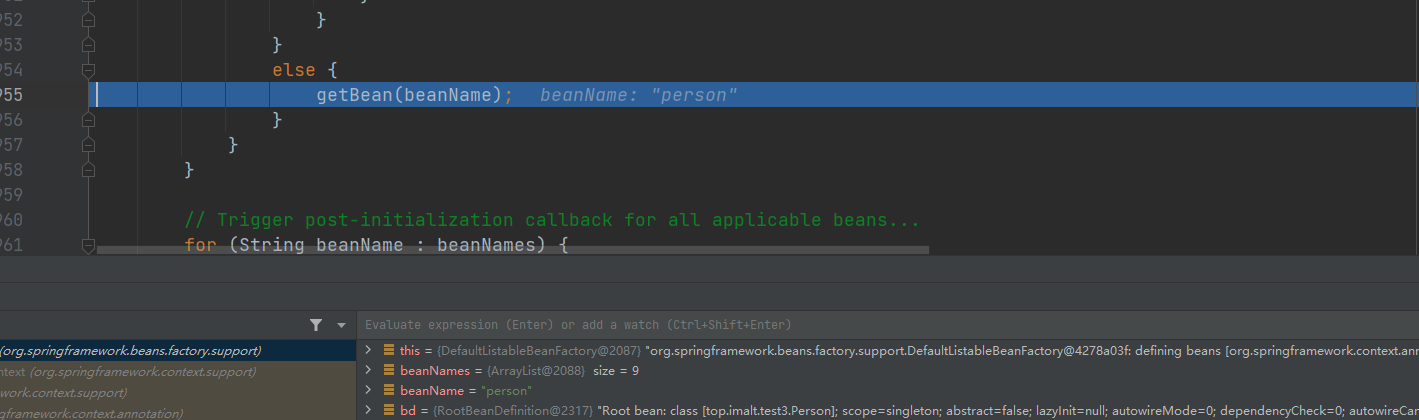
getBean() 进入
进入 doGetBean () 方法 ,createBean 创建 LifeCycleBean 的逻辑。

实例化
doCreateBean() 方法 调用 createBeanInstance() 方法1
2
3
4
5
- ```java
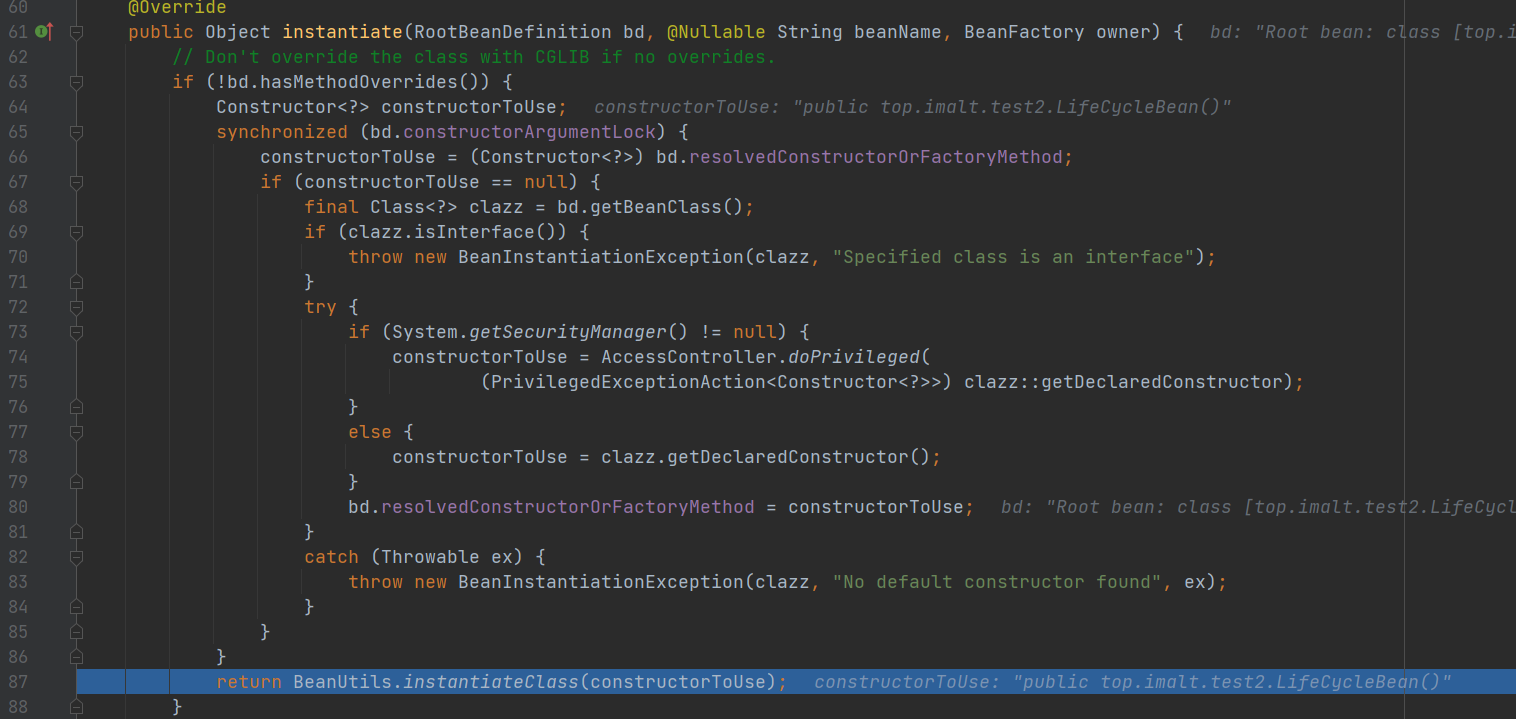
createBeanInstance() 方法中 调用 instantiateBean() 方法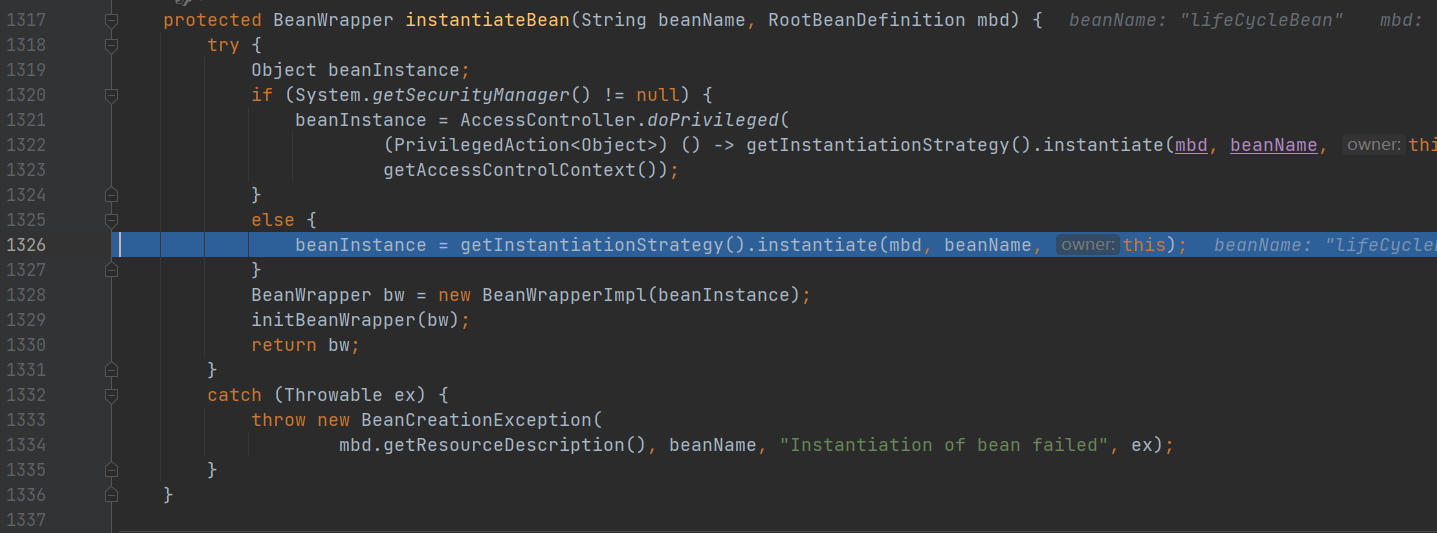
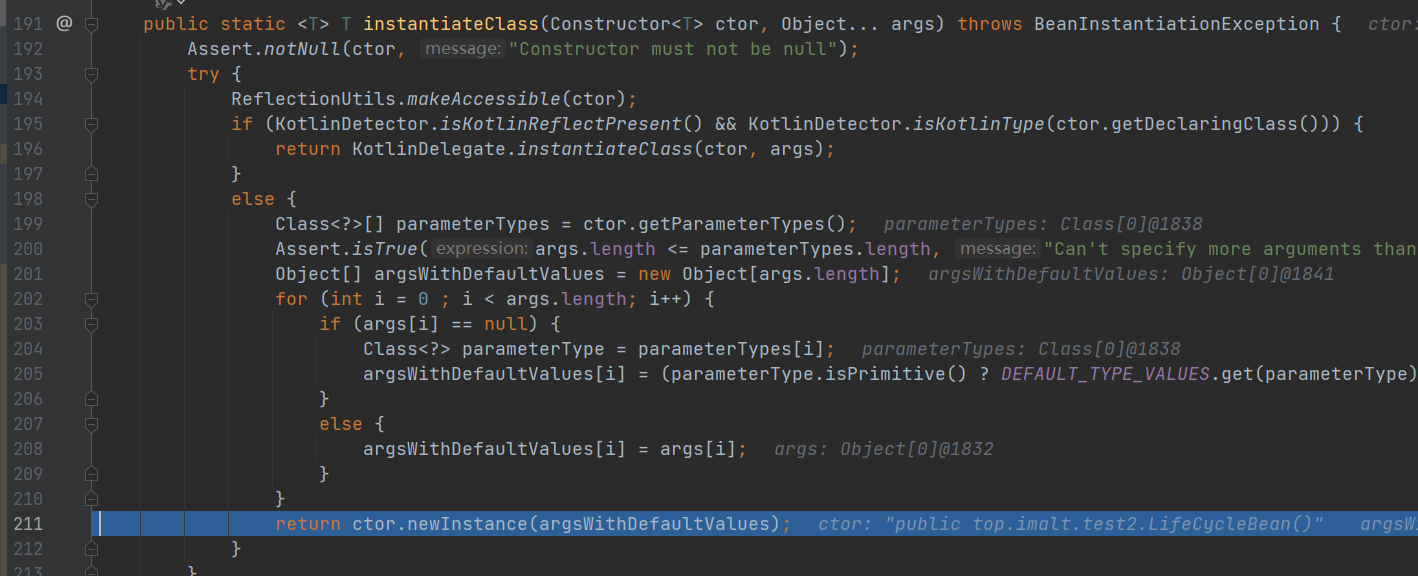
BeanUtils.instantiateClass() // 反射调用1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
- 
- 
- 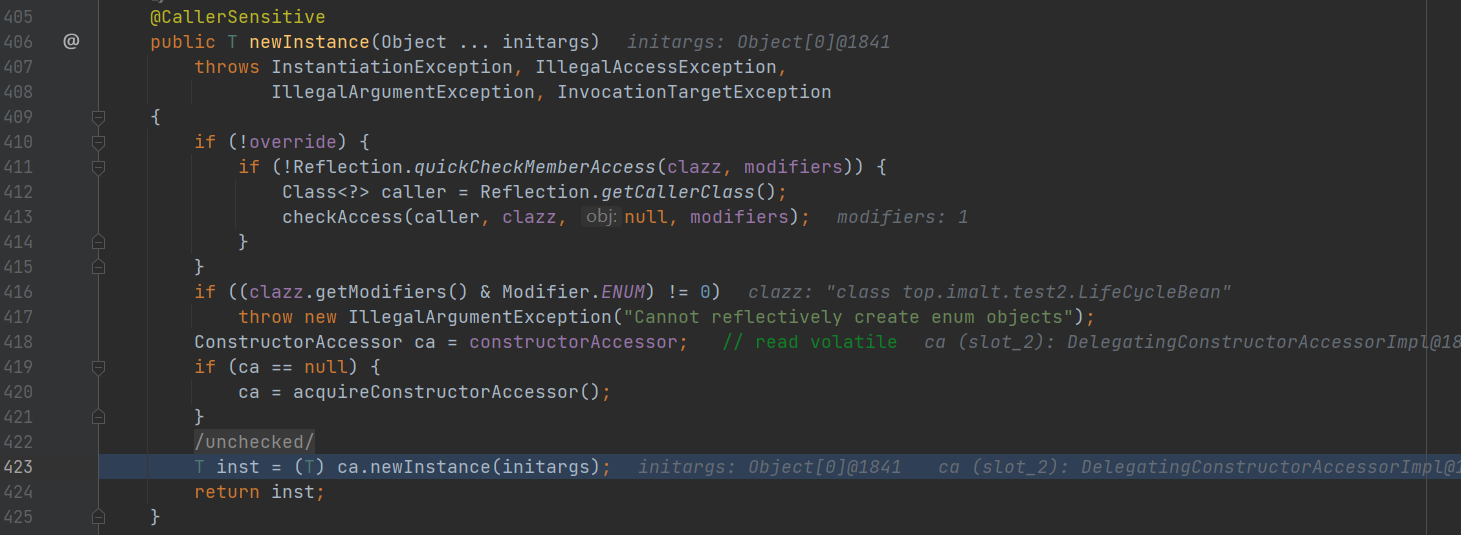
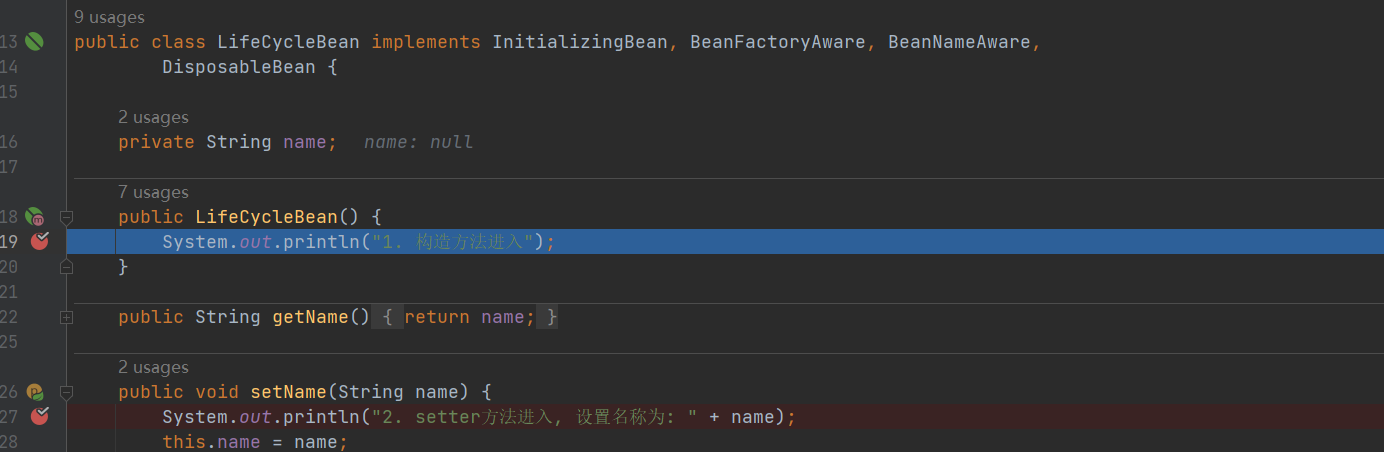
- 再进入 执行构造方法 实例化对象
- 
### 属性赋值
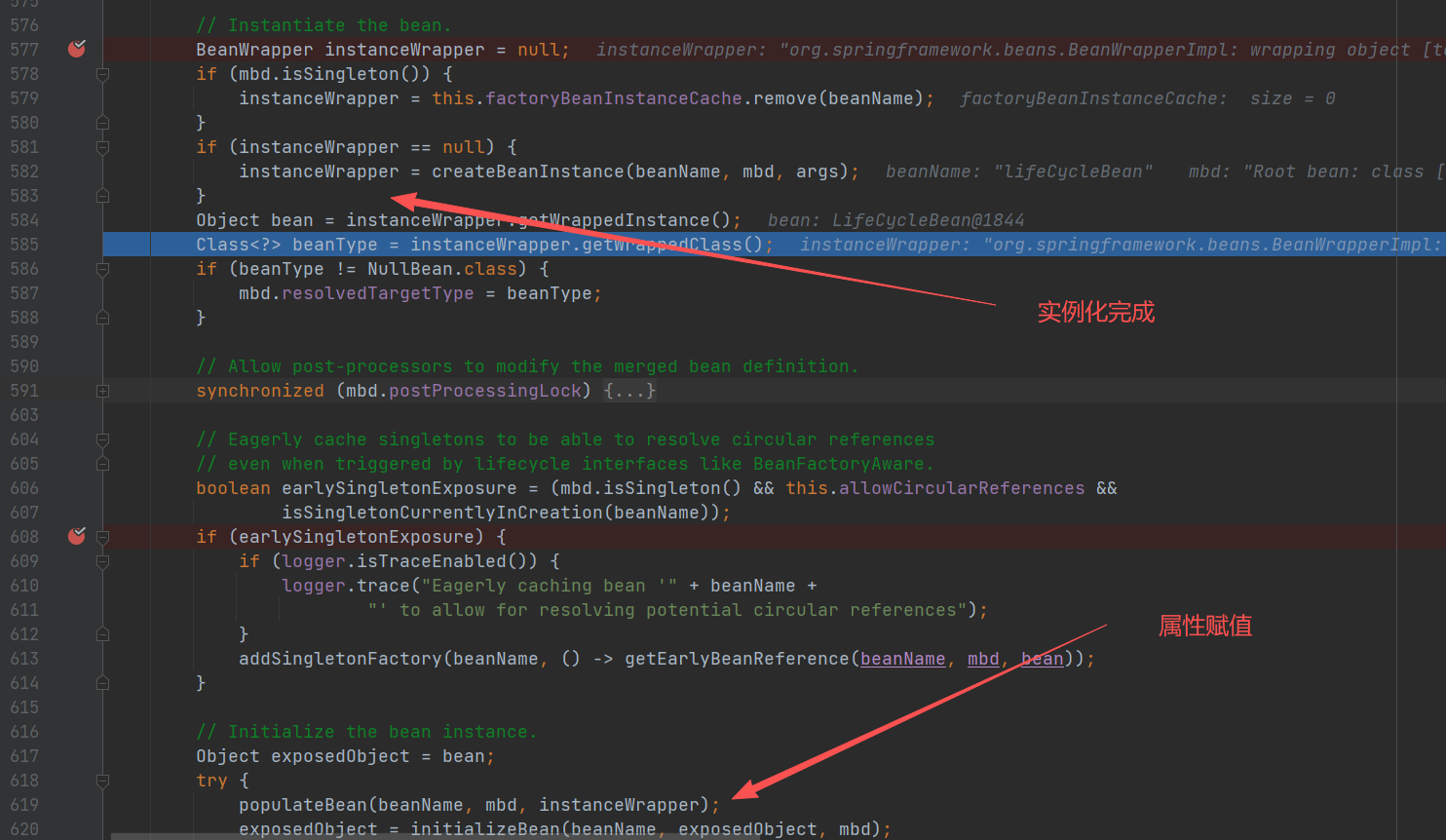
再回到doCreateBean(),继续往后⾛走,进⼊populateBean()。
- 这个方法非常重要,里面其实就是依赖注入的逻辑,具体参考第一章 Spring 循环依赖。
- 
- 进入populateBean() 执行 applyPropertyValues() 方法



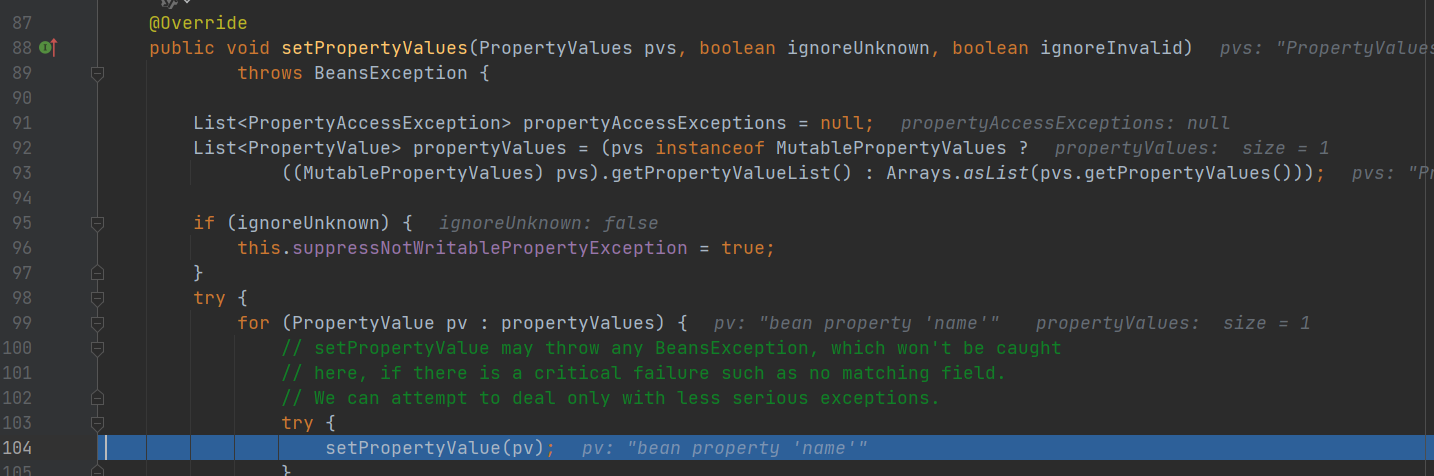
继续断点,直到setValue() 方法
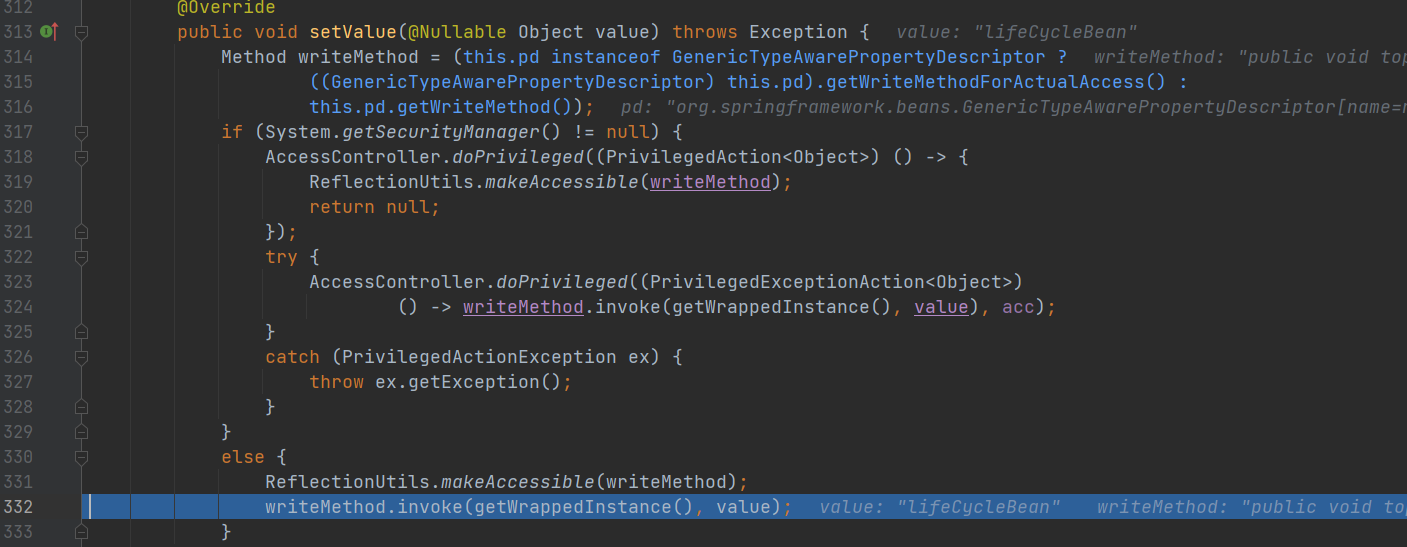
属性赋值,回调setName() 方法

### 初始化
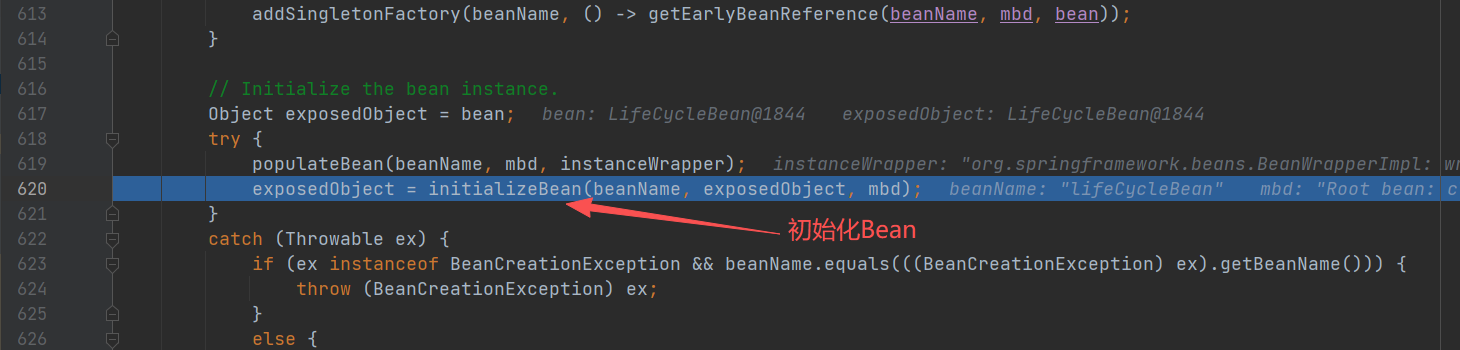
继续回到 doCreateBean(),往后执行 initializeBean()
- 核心 一 处理Aware 接口:invokeAwareMethods(beanName, bean);
- 1.BeanNameAware接口
- 2.BeanClassLoaderAware接口
- 3.BeanFactoryAware接口
- 核心 二 处理 BeanPostProcessor 接口 - postProcessorsBeforeInitialization 方法: applyBeanPostProcessorsBeforeInitialization(wrappedBean, beanName)
- 框架内置:**ApplicationContextAwareProcessor**
- 处理指定接Aware接口:EnvironmentAware、EmbeddedValueResolverAware、ResourceLoaderAware、ApplicationEventPublisherAware、MessageSourceAware、ApplicationContextAware、ApplicationStartupAware
- 非以上指定Aware接口直接返回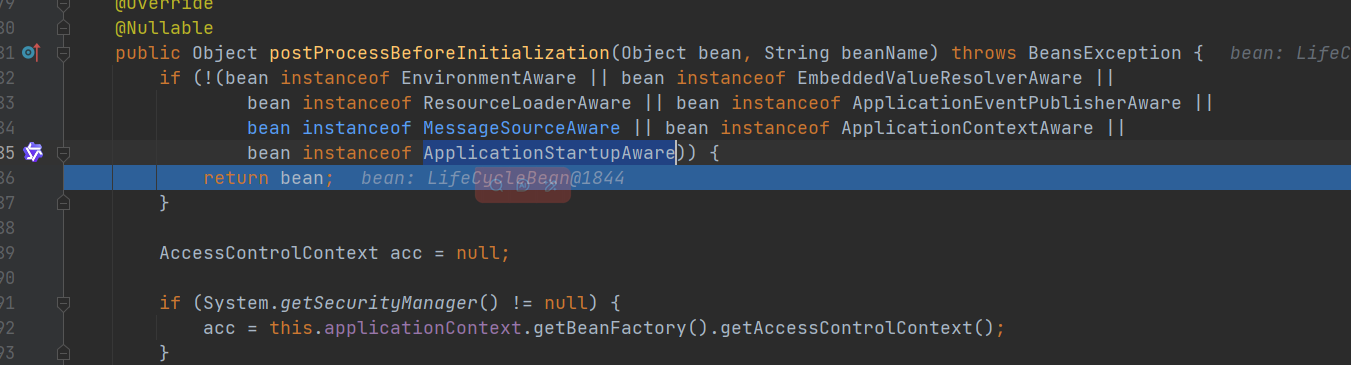
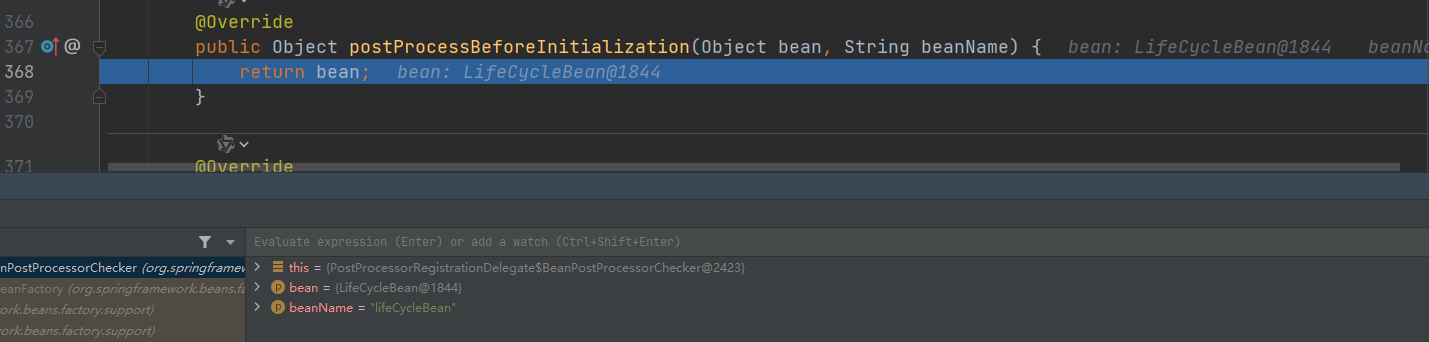
- 框架内置:PostProcessorRegistrationDelegate
- 直接返回
- 
- 自定义:lifeCycleBeanPostProcessor
- 
-
- 框架内置:ApplicationListenerDetector
- 核心 三 处理 初始化init()方法 :invokeInitMethods(beanName, wrappedBean, mbd);
- 核心 四 处理 BeanPostProcessor 接口 - postProcessorsAfterInitialization 方法:applyBeanPostProcessorsAfterInitialization(wrappedBean, beanName);
#### 核心一:invokeAwareMethods()
- 1.处理BeanNameAware接口,设置BeanName
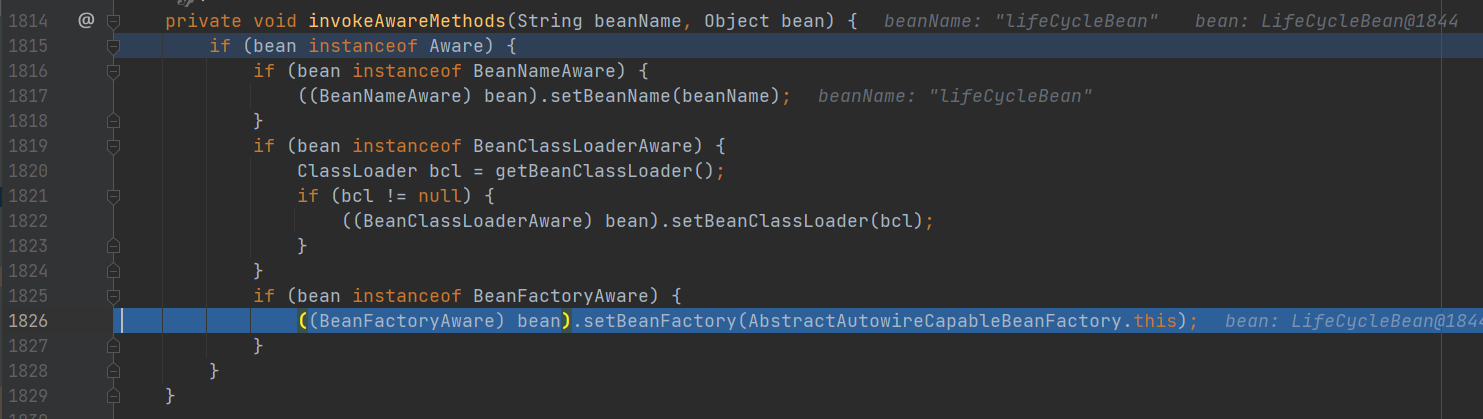
- 3.处理BeanFactoryAware接口

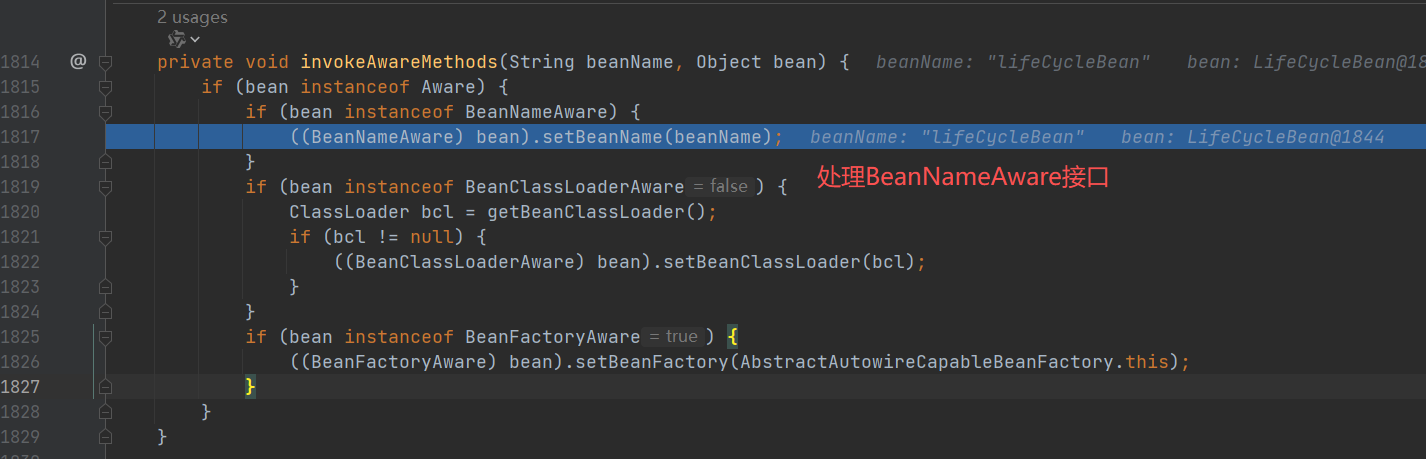

- 2.处理BeanClassLoaderAware接口
- 3.处理BeanFactoryAware接口

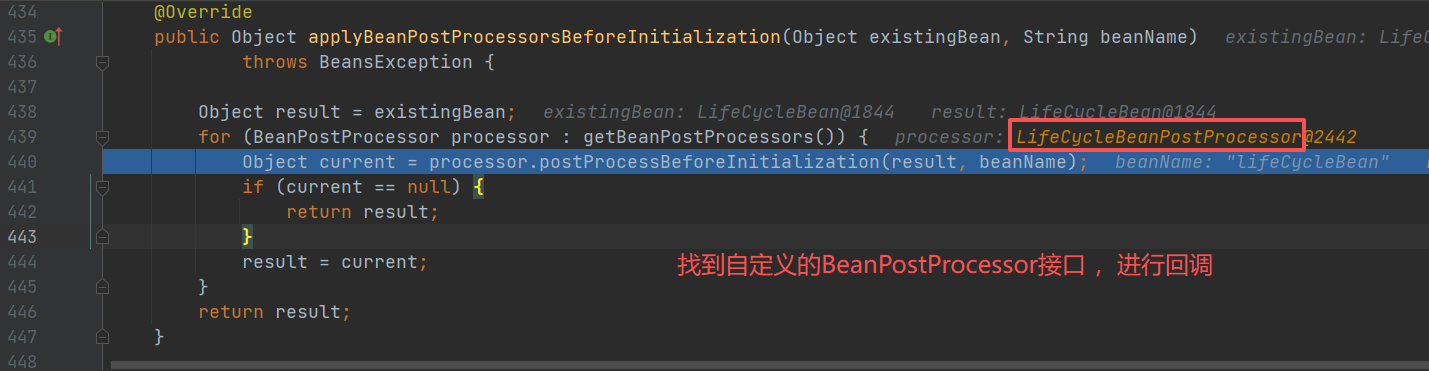
#### 核心二:applyBeanPostProcessorsBeforeInitialization()
找到自定义的LifeCycleBeanPostProcessor 的类,执行postProcessBeforeInitialization() 方法

获取所有BeanPostProcessors接口,循环进行调用

#### 核心三:invokeInitMethods
- 1.先执行InitializingBean 接口
- 2.再执行自定义的初始化接口

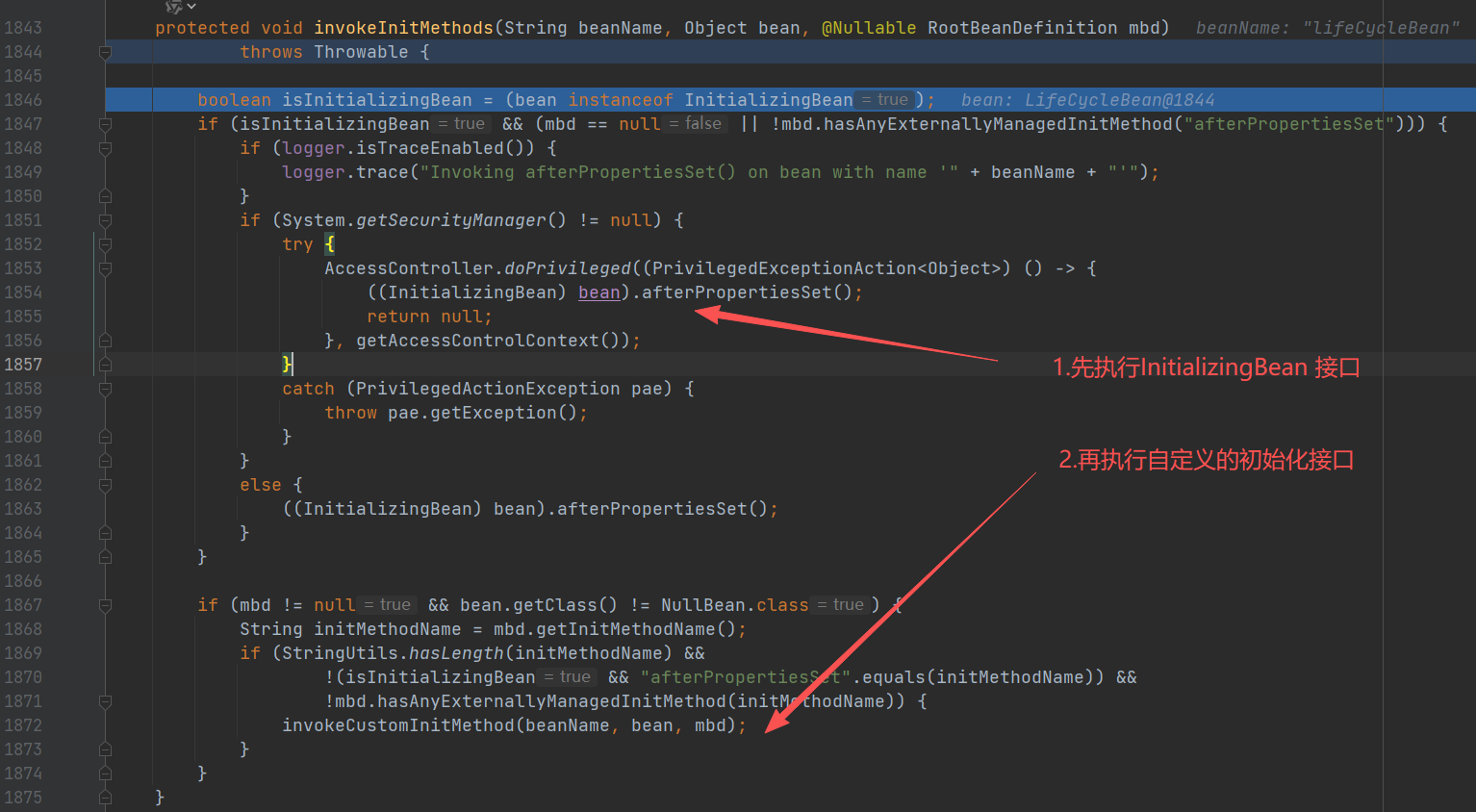
- 先执行 InitializingBean 接口的 afterPropertiesSet() 方法

再执行invokeCustomInitMethod()


#### 核心四:applyBeanPostProcessorsAfterInitialization
找到自定义的LifeCycleBeanPostProcessor 的类,执行postProcessAfterInitialization() 方法


到这里,初始化的流程全部结束,都是围绕 initializeBean() 展开。
### 销毁
```java
((ClassPathXmlApplicationContext) context2).close();
1 | public void close() { |
doClose() 方法中:


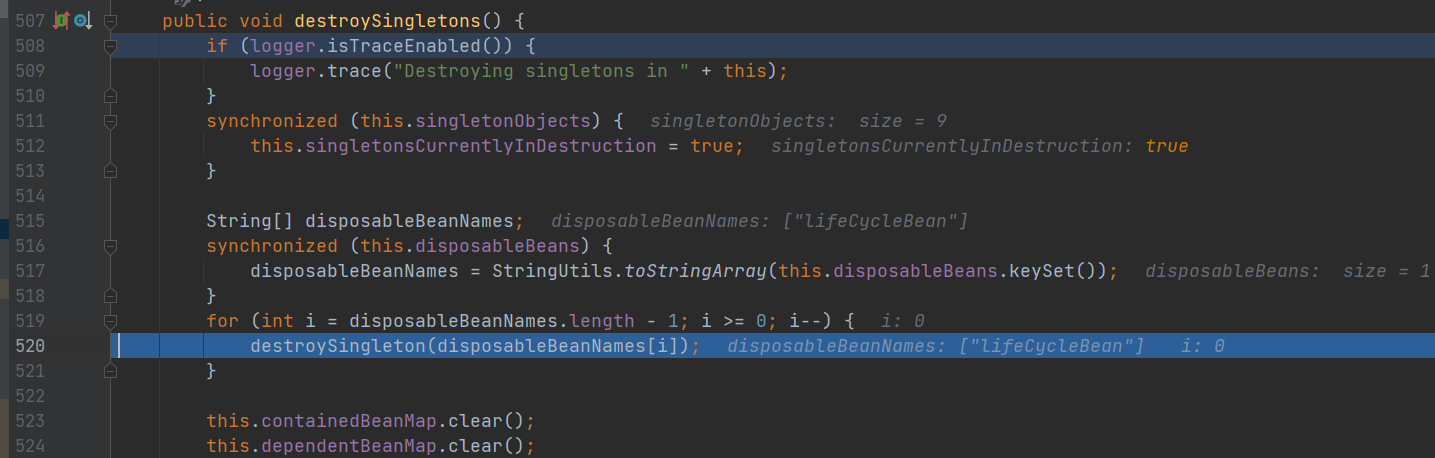


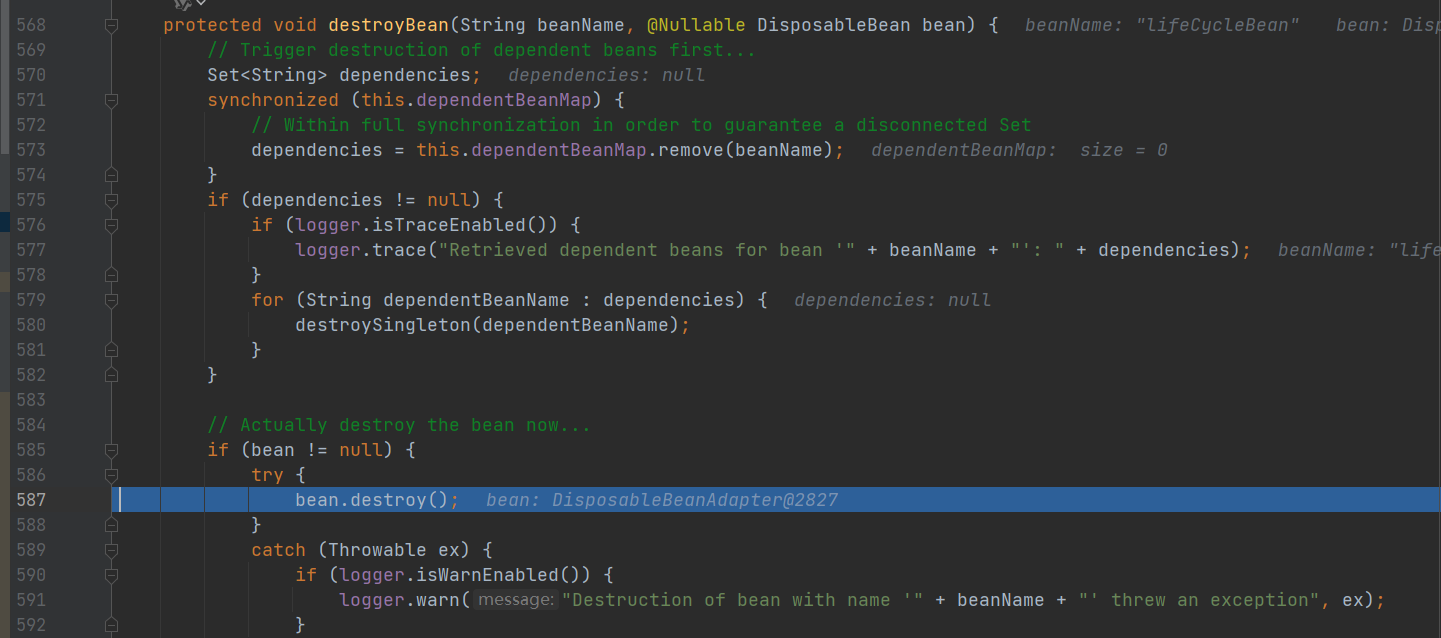
DisposableBeanAdapter 类 destroy()
- 1.处理BeanPostProcessor 子接口 DestructionAwareBeanPostProcessor 接口: processor.postProcessBeforeDestruction(this.bean, this.beanName)
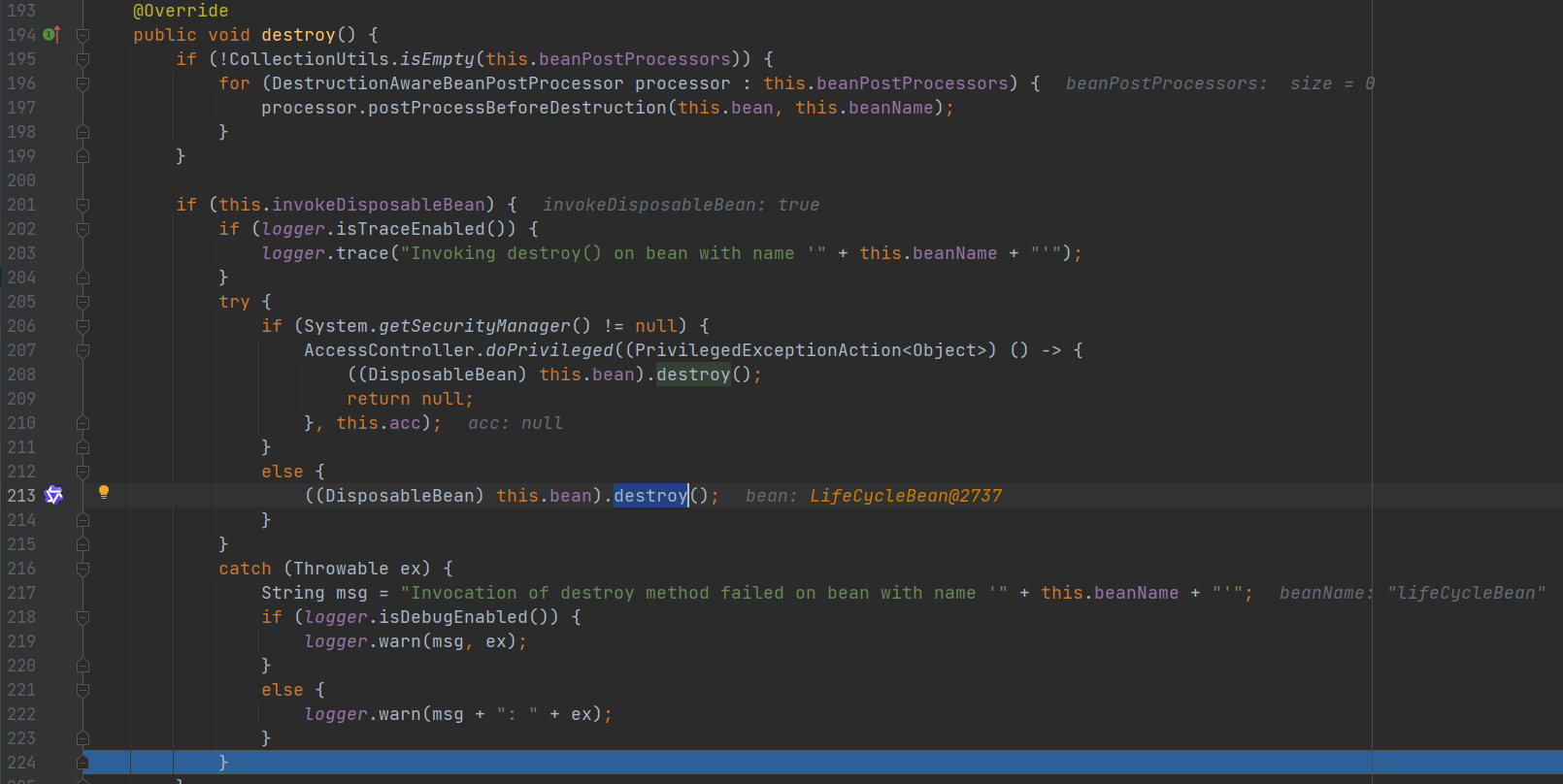
- 2.处理DisposableBean接口: ((DisposableBean) this.bean).destroy()
- 3.处理AutoCloseable接口: ((AutoCloseable) this.bean).close()
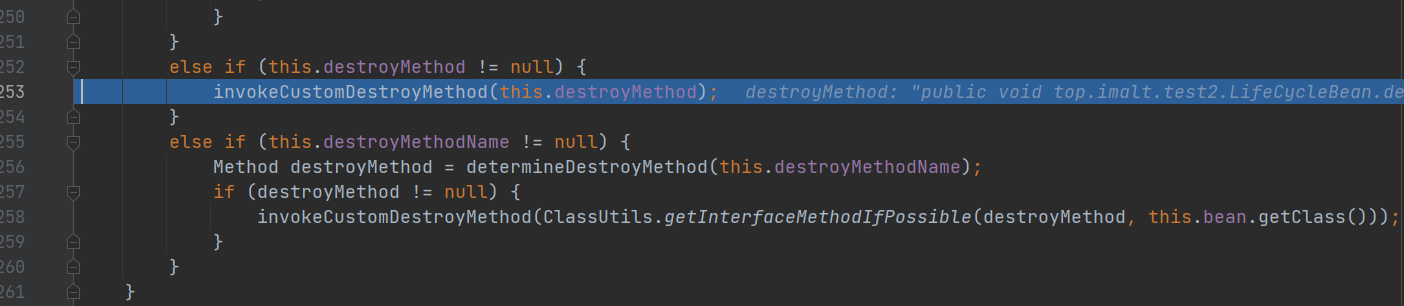
- 4.处理自定义的销毁方法: invokeCustomDestroyMethod(this.destroyMethod)
处理DisposableBean 接口:

处理自定义的销毁方法

Spring AOP
基础知识
什么是AOP
AOP 的全称是 “Aspect Oriented Programming”,即面向切面编程,通过预编译方式和运行期动态代理实现程序功能的统一维护的一种技术。
在 AOP 的思想里面,周边功能(比如性能统计,日志,事务管理等)被定义为切面,核心功能和切面功能分别独立进行开发,然后把 核心功能和切面功能“编织“在一起,从而使业务逻辑各部分之间的耦合度降低,提高程序的可重用性,同时提高开发效率。
基本概念
| 概念 | 含义 |
|---|---|
| 切面(aspect) | 类是对物体特征的抽象,切面就是对横切关注点的抽象 |
| 横切关注点 | 对哪些方法进行拦截,拦截后怎么处理,这些关注点称为横切关注点 |
| 连接点(joinpoint) | 被拦截到的点:Spring AOP 是基于动态代理的,所以是方法拦截的,每个成员方法都可以称之为连接点 |
| 切入点(pointcut) | 对连接点进行拦截的定义:每个方法都可以称之为连接点,我们具体定位到某一个方法就成为切点 |
| 通知(advice) | 拦截到连接点之后要执行的代码,通知分为前置、后置、异常、最终、环绕通知五类 |
| 织入(weave) | 将切面应用到目标对象并导致代理对象创建的过程 |
| 引入(introduction) | 在不修改代码的前提下,引入可以在运行期为类动态地添加一些方法或字段 |
五种通知类型
- 前置通知(Before Advice):在目标方法被调用前调用通知功能;
- 后置通知(After Advice):在目标方法被调用之后调用通知功能;
- 返回通知(After-returning):在目标方法成功执行之后调用通知功能;
- 异常通知(After-throwing):在目标方法抛出异常之后调用通知功能;
- 环绕通知(Around):把整个目标方法包裹起来,在被调用前和调用之后分别调用通知功能。
执行流程
1 |
|
1 | // 运行结果 |
具体工作流程分为三部分
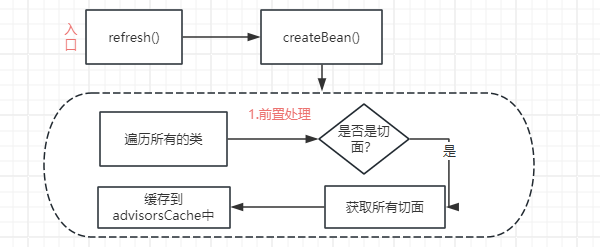
1.前置处理,在创建 Person 的前置处理中,会遍历程序所有的切面信息,然后将切面信息保存在缓存中,比如示例中 PersonAspect 的所有切面信息。
2.后置处理
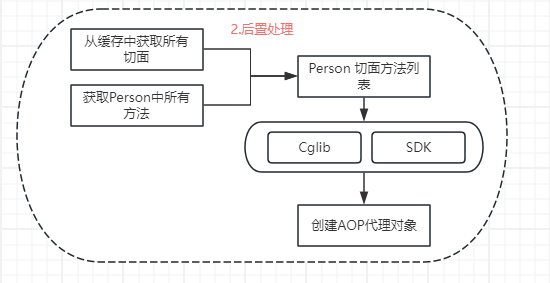
- 获取 Person 的切面方法:首先会从缓存中拿到所有的切面信息,和 Person 的所有方法进行匹配,然后找到 Person 所有需要进行 AOP 的方法。
- 创建 AOP 代理对象:结合 Person 需要进行 AOP 的方法,选择 Cglib 或JDK,创建 AOP 代理对象
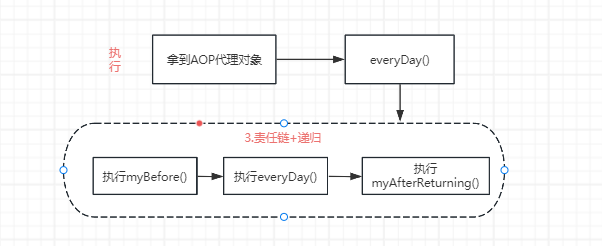
3.执行方法:通过“责任链 + 递归”,去执⾏切⾯
源码解读
代码入口
1 | //AbstractApplicationContext 类 |

前置处理
createBean()方法中
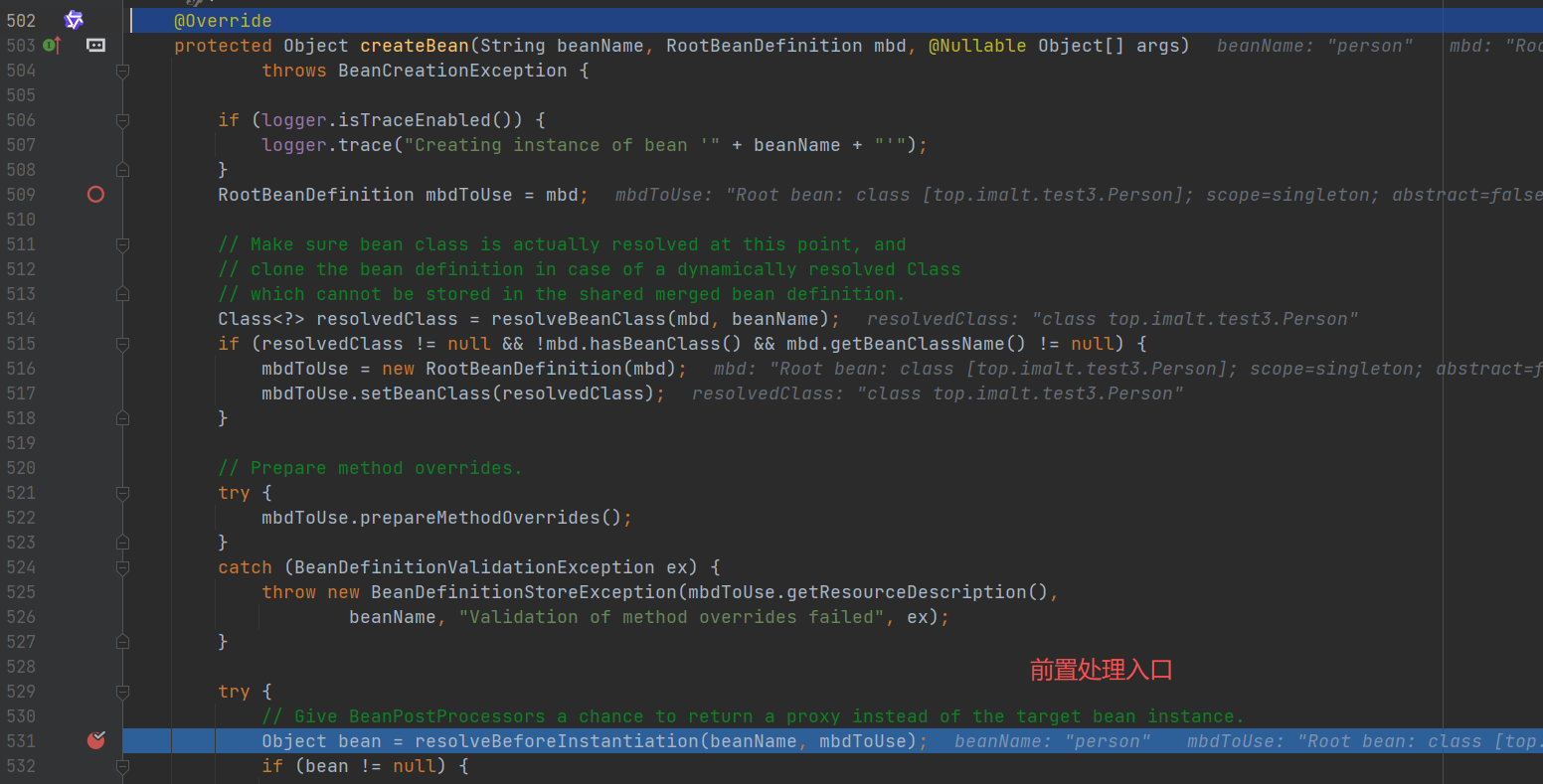
前置处理
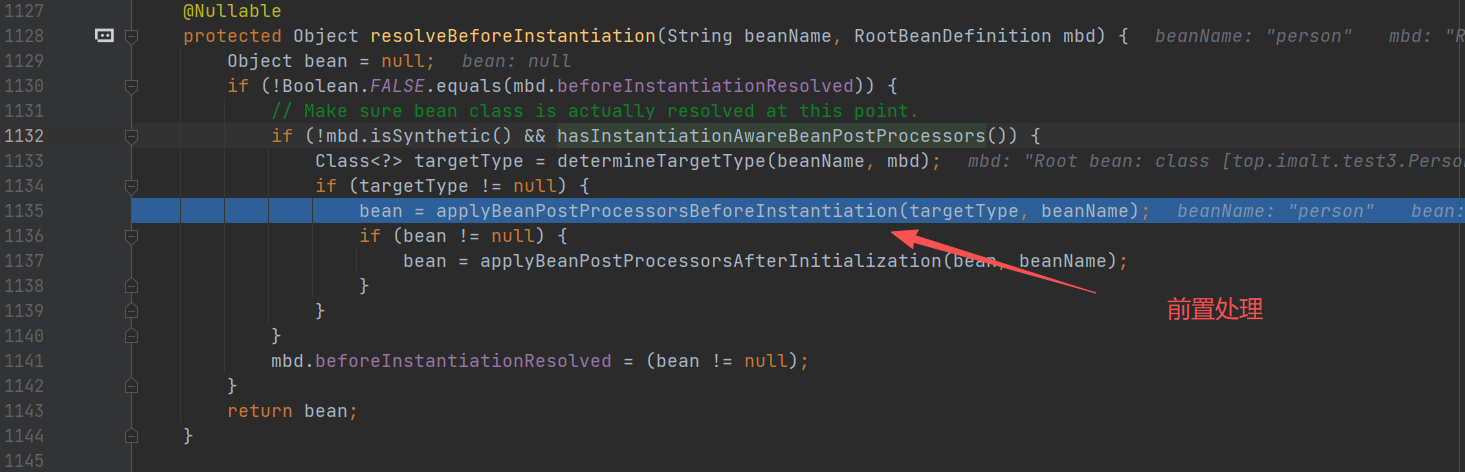
策略模式找到 AnnotationAwareAspectJAutoProxyCreator 进行处理 postProcessBeforeInstantiation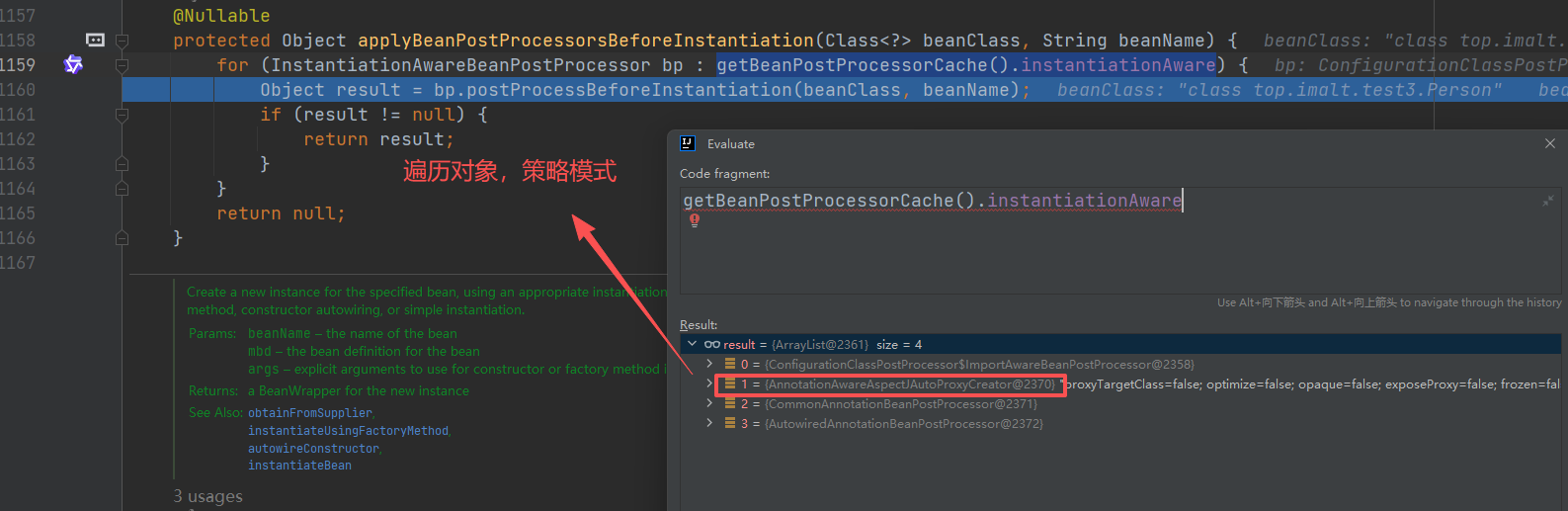
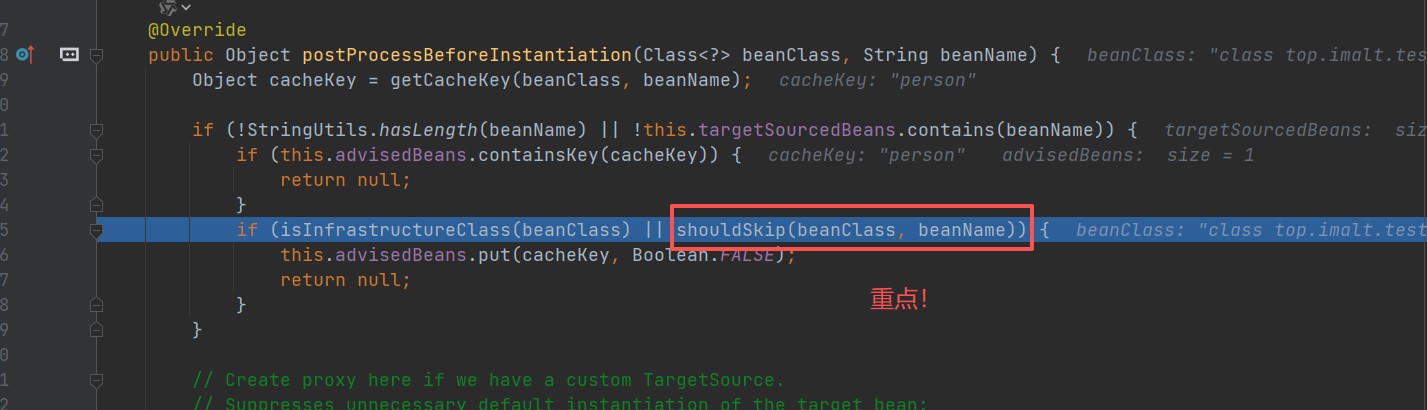
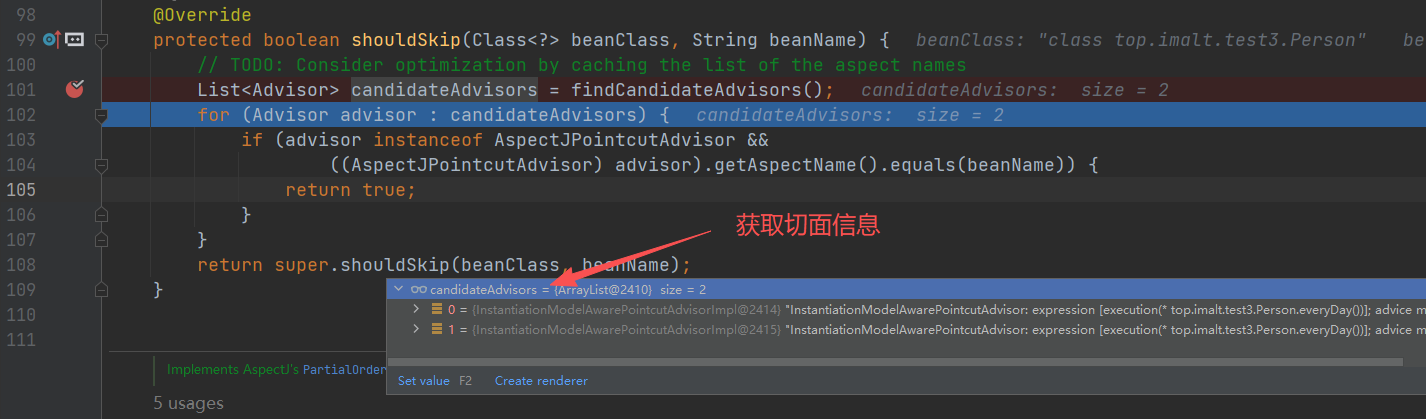
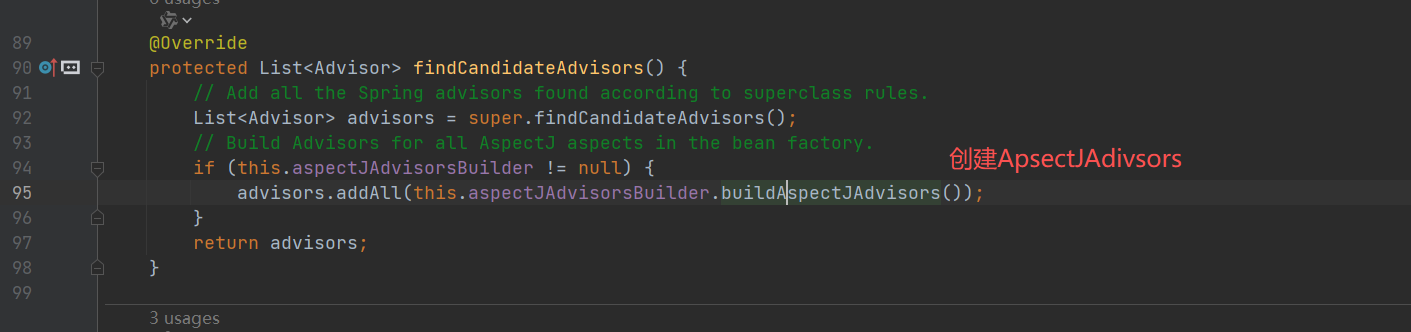
重点
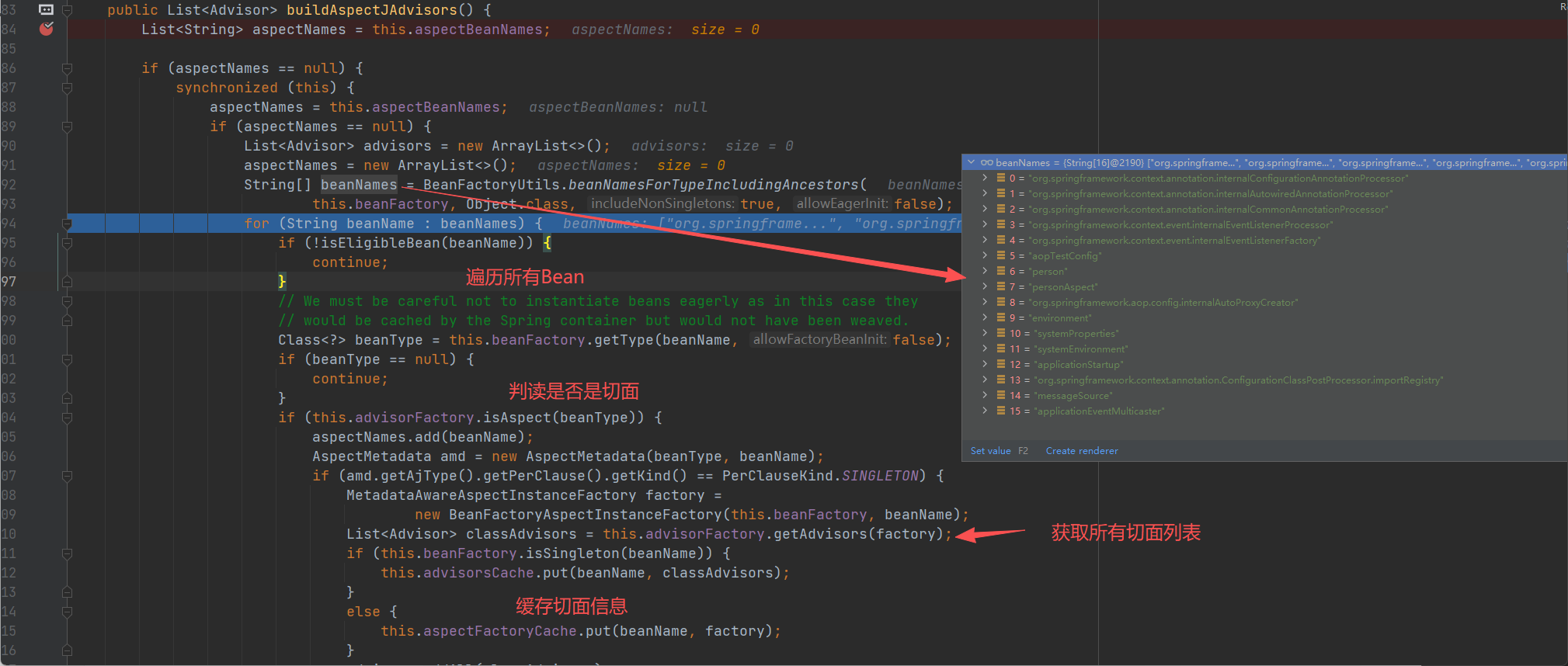
- 先遍历所有的类
- 判断是否切⾯,只有切面才会进入后⾯逻辑
- 获取每个 Aspect 的切面列表;
- 保存 Aspect 的切面列表到缓存 advisorsCache 中。
最终找到自定义 的PersonAspect 类,然后缓存两个切面列表
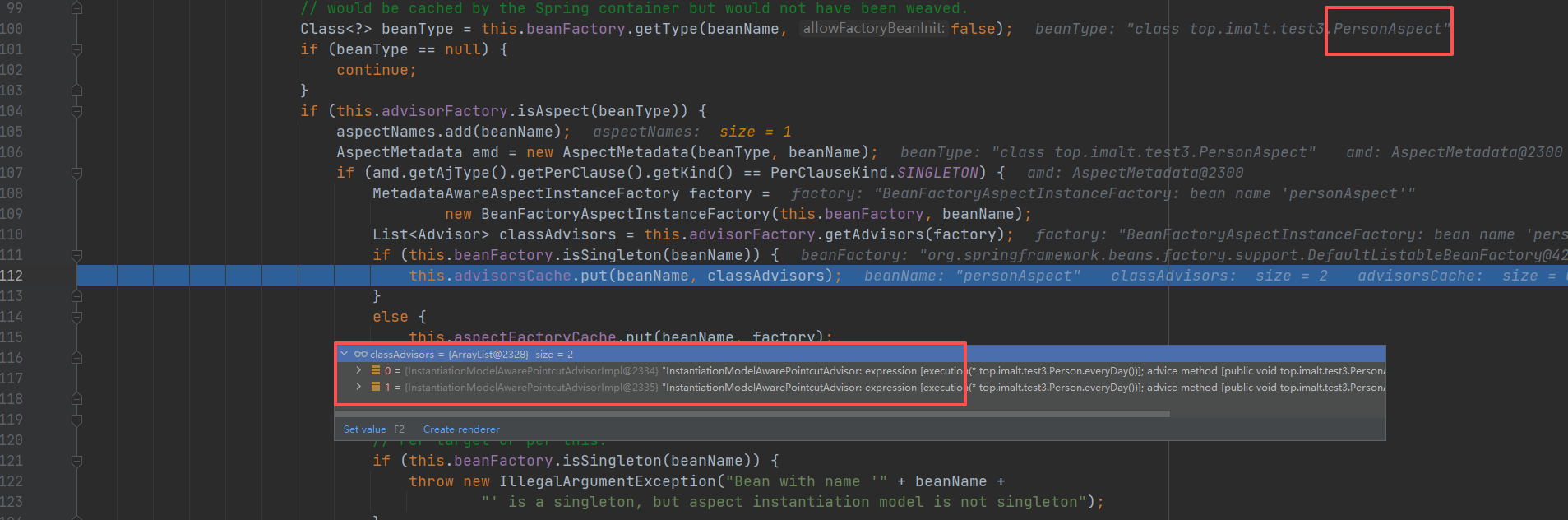
判断是否切⾯

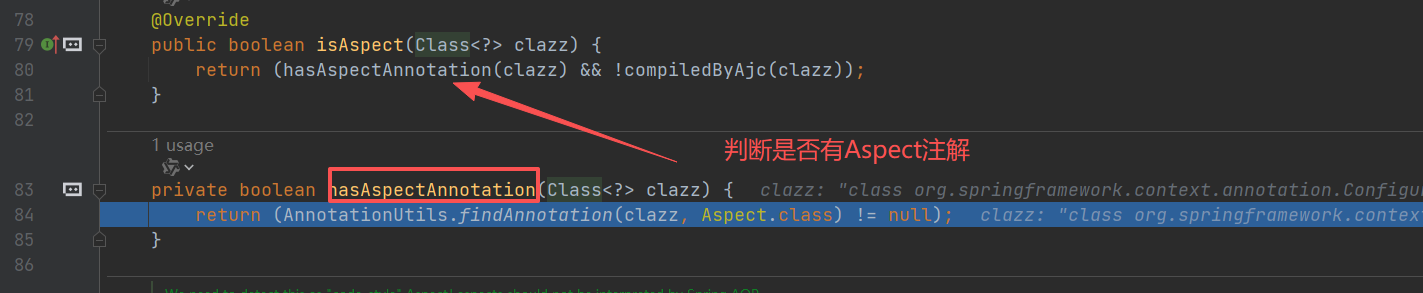
获取切面列表
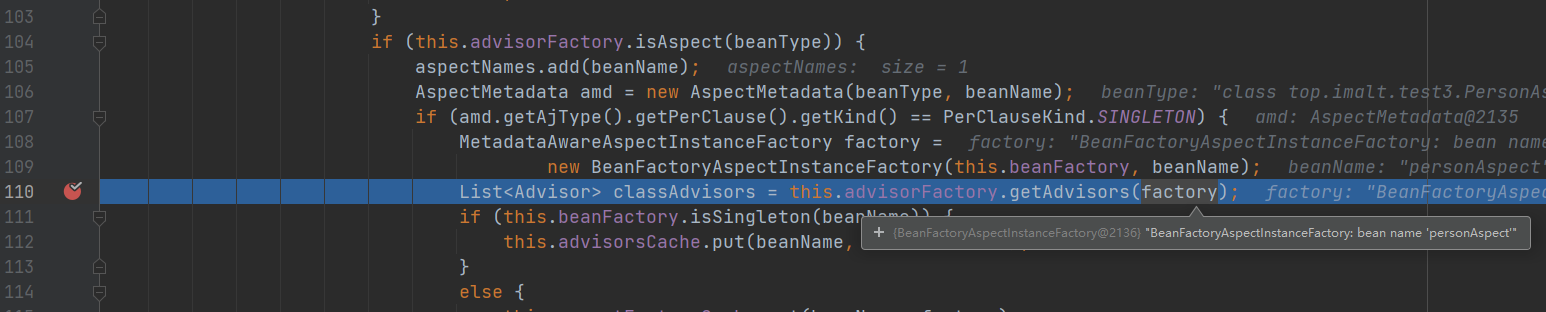
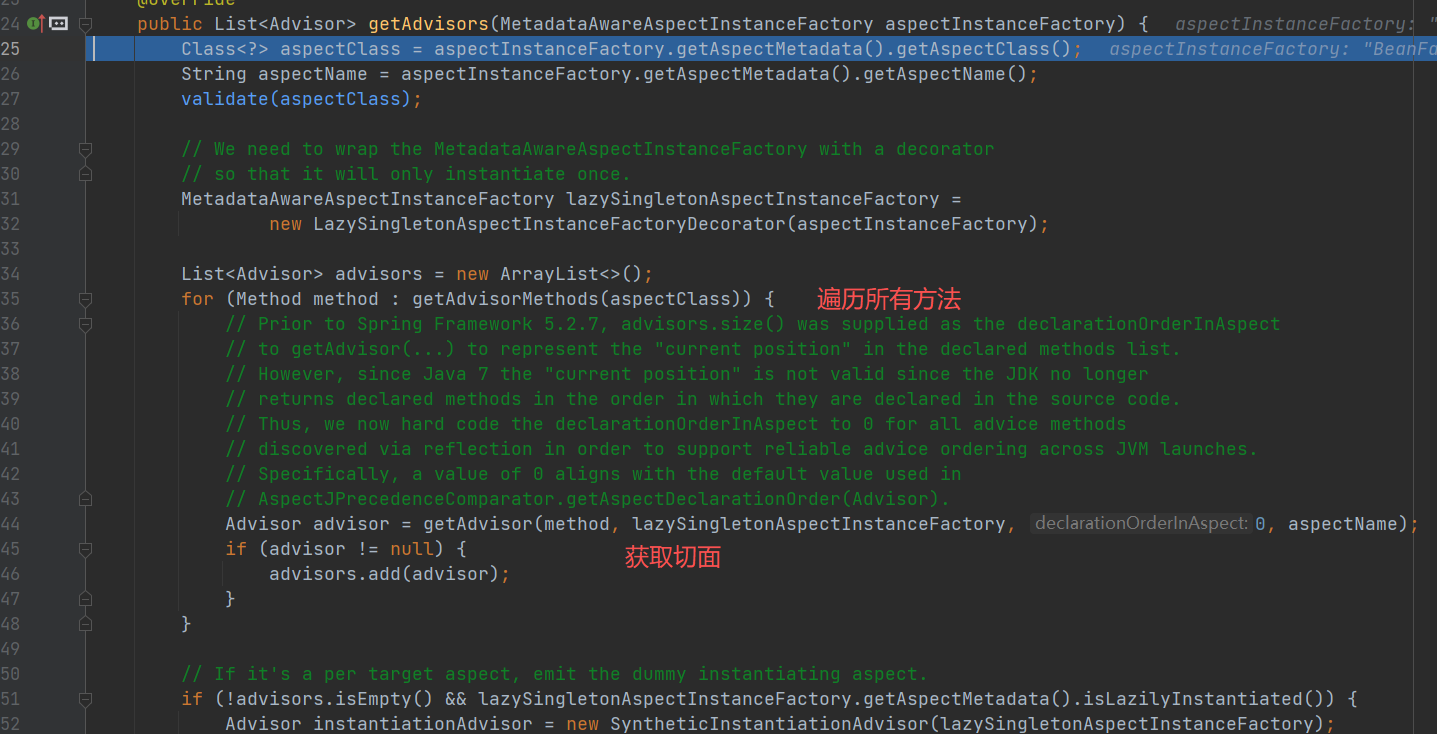
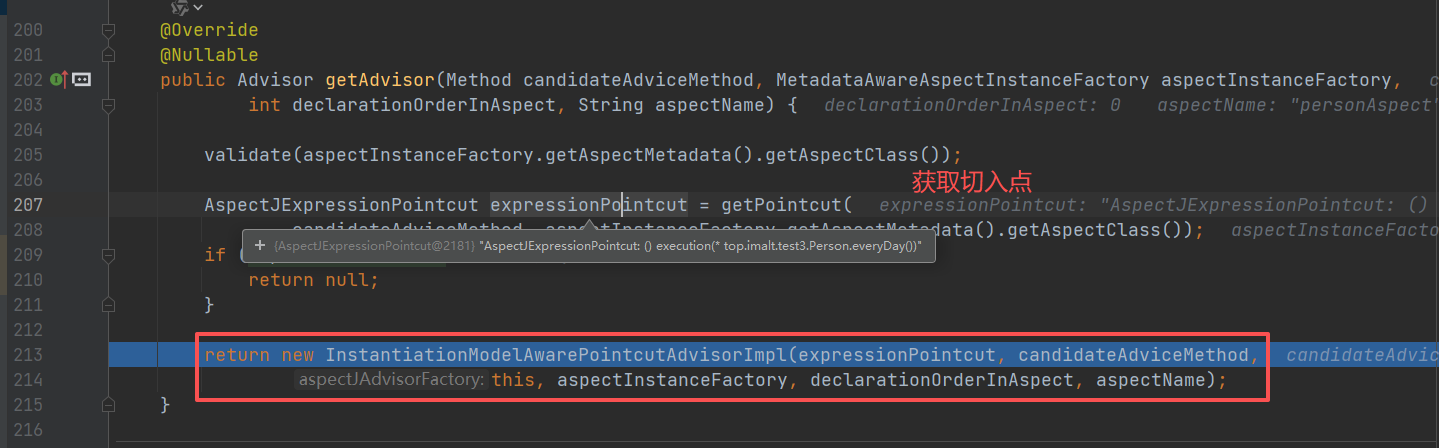
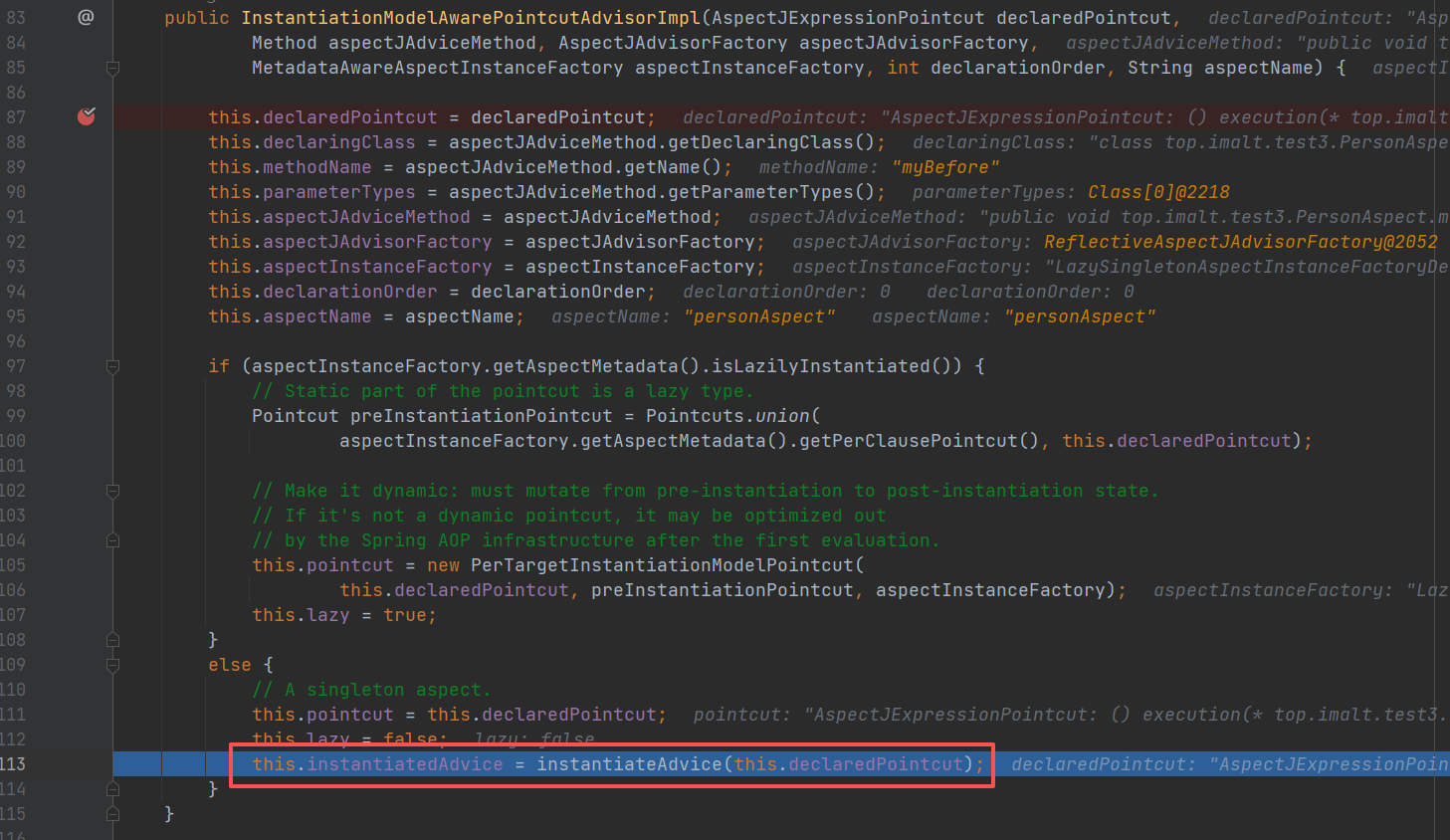
利用aspectJAdvisorFactory 获取 切面

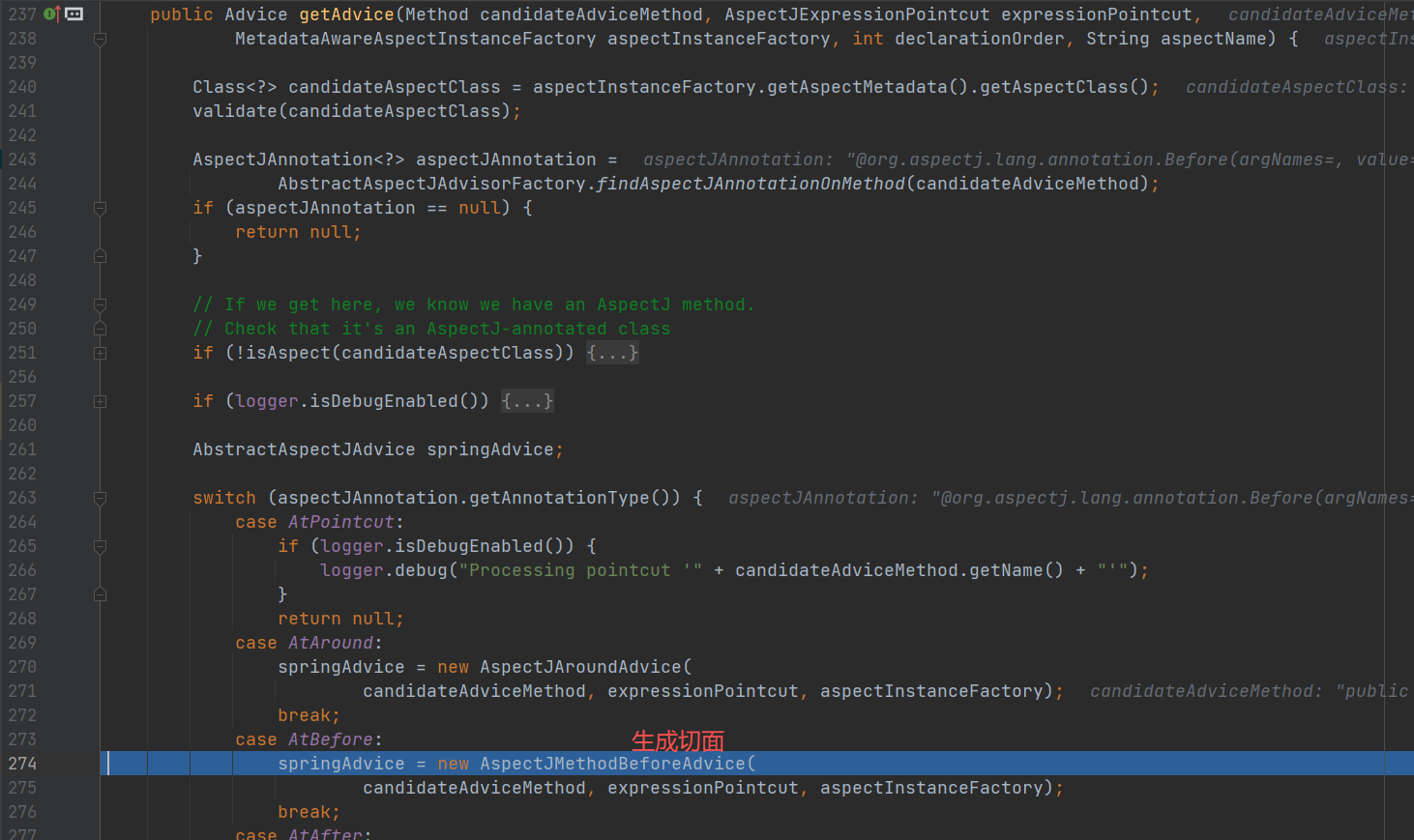
后置处理
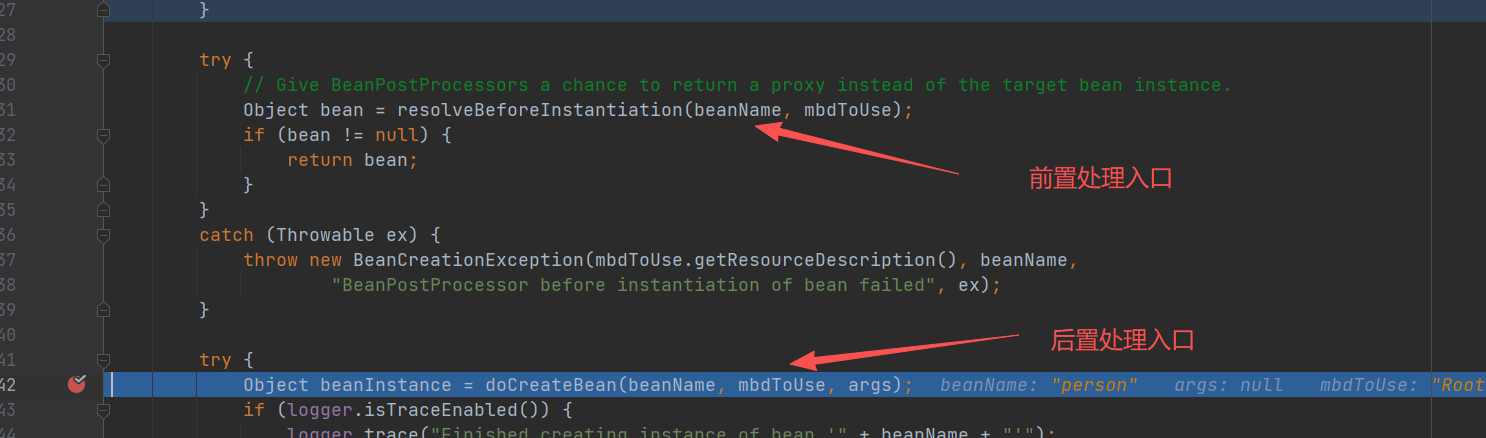

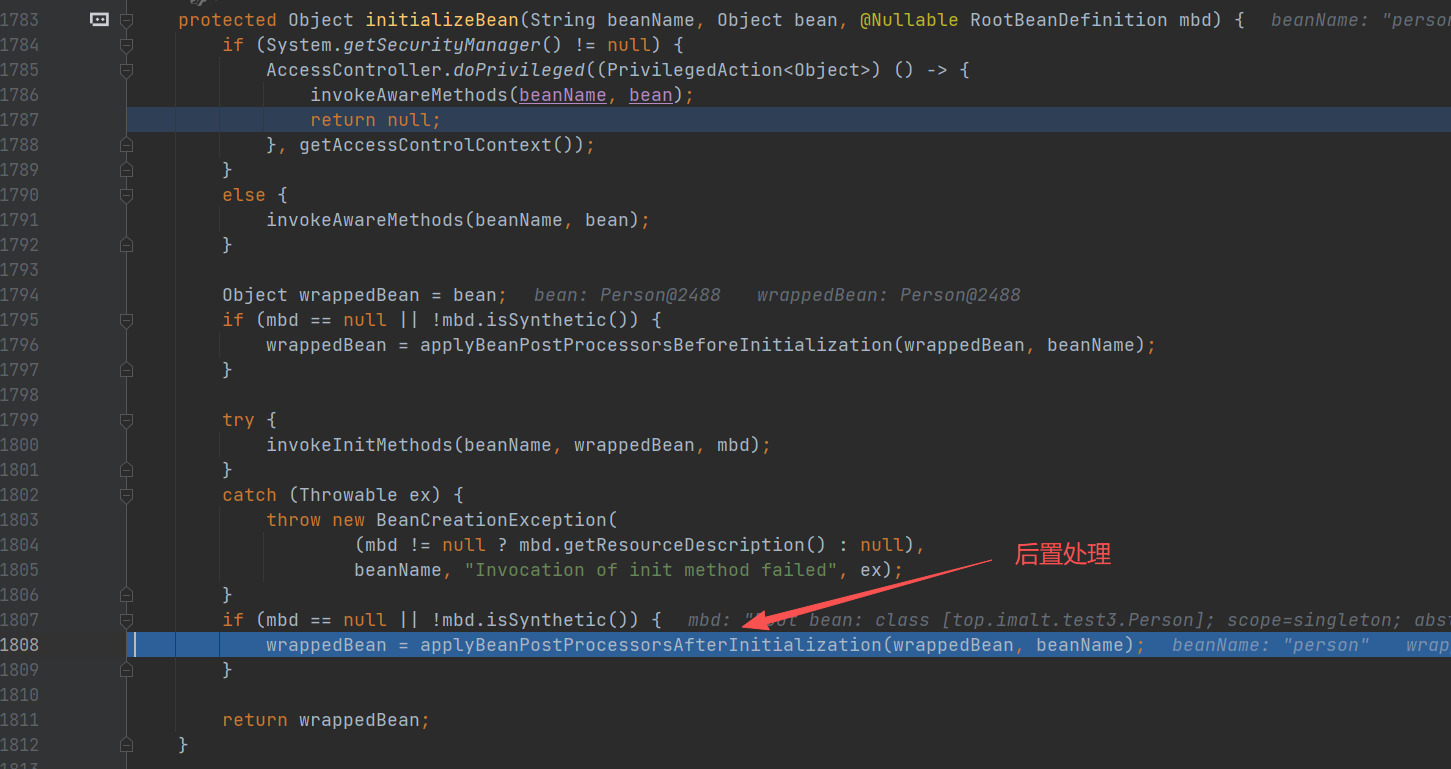
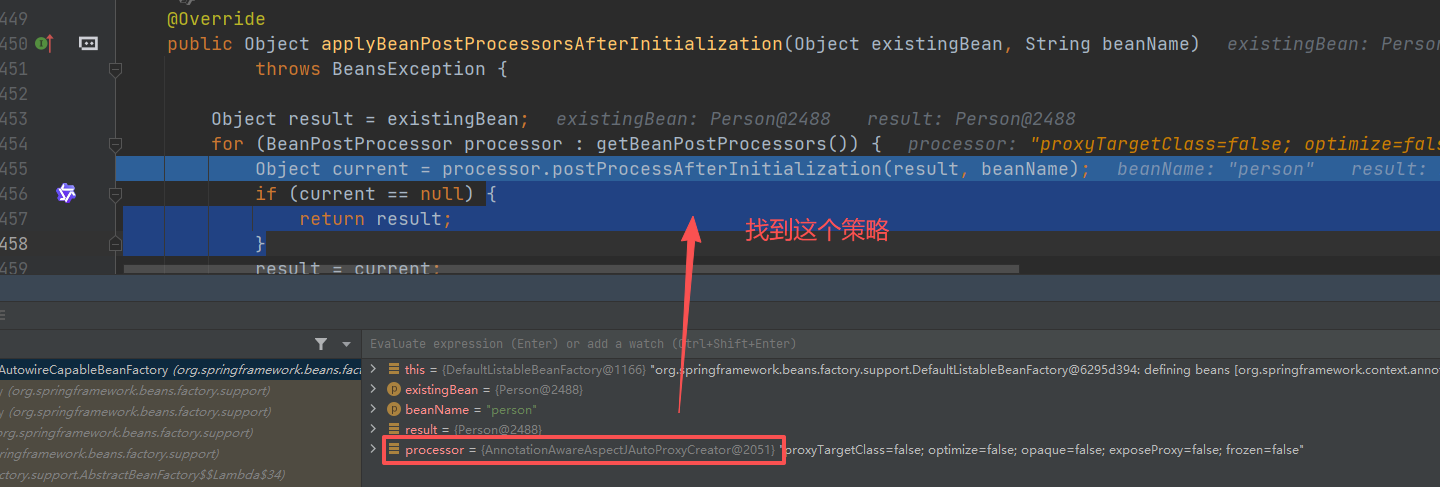
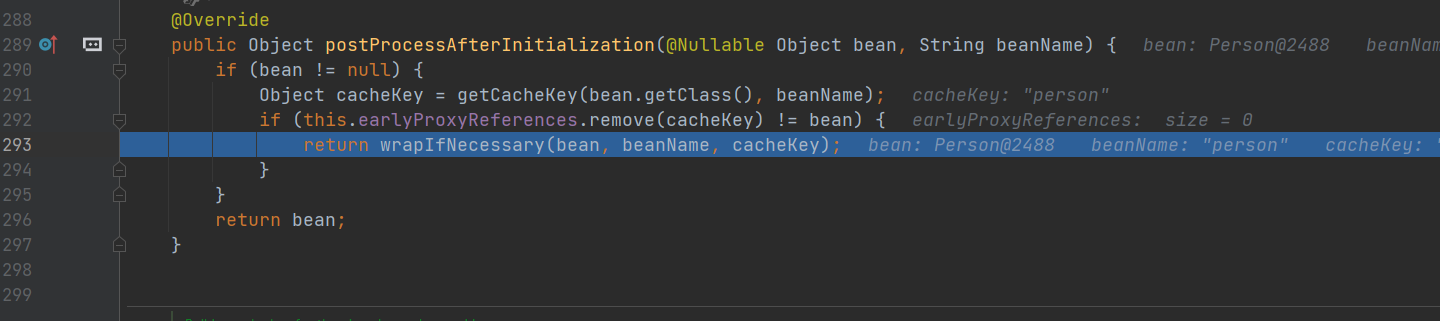
重点
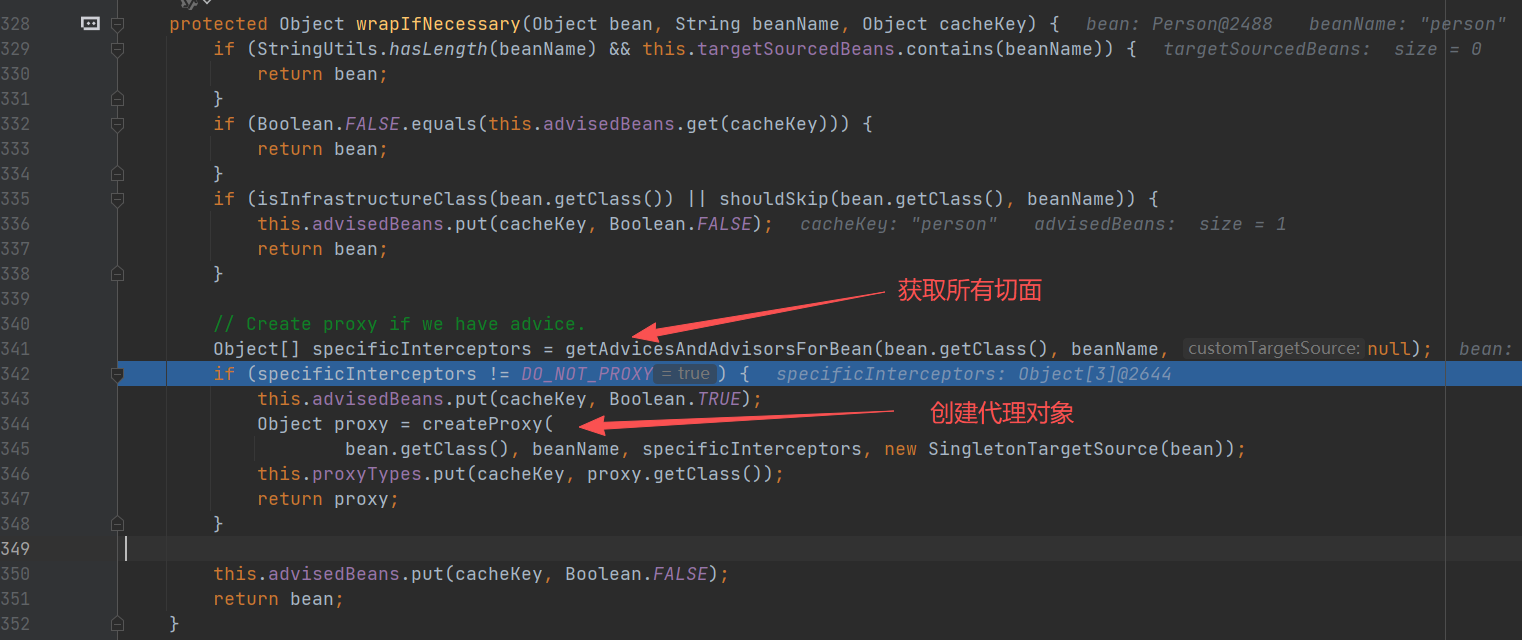
获取所有切面
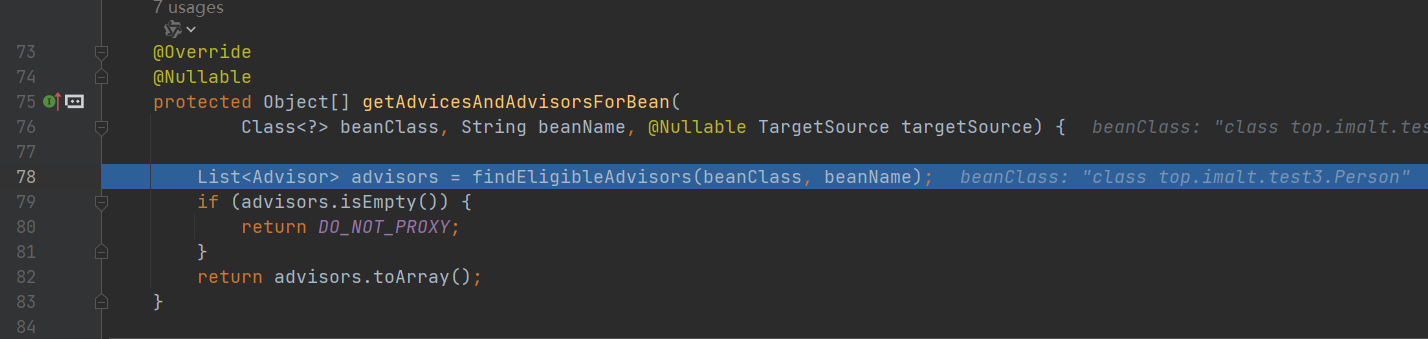
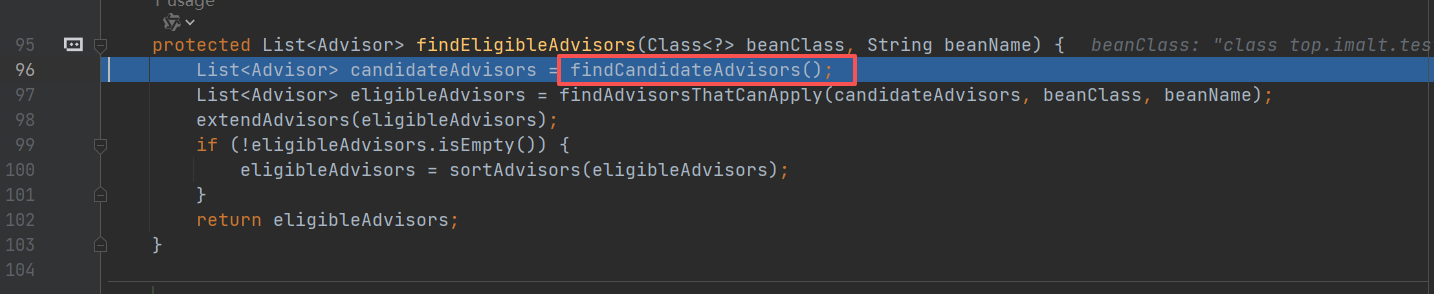
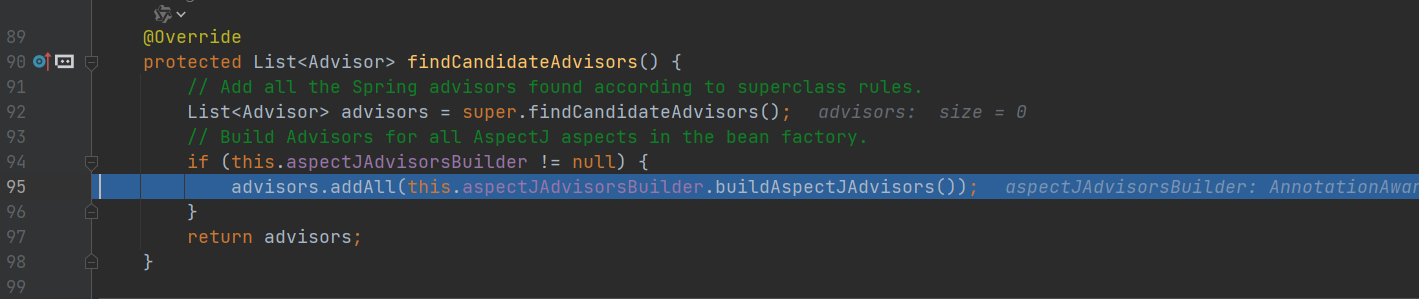
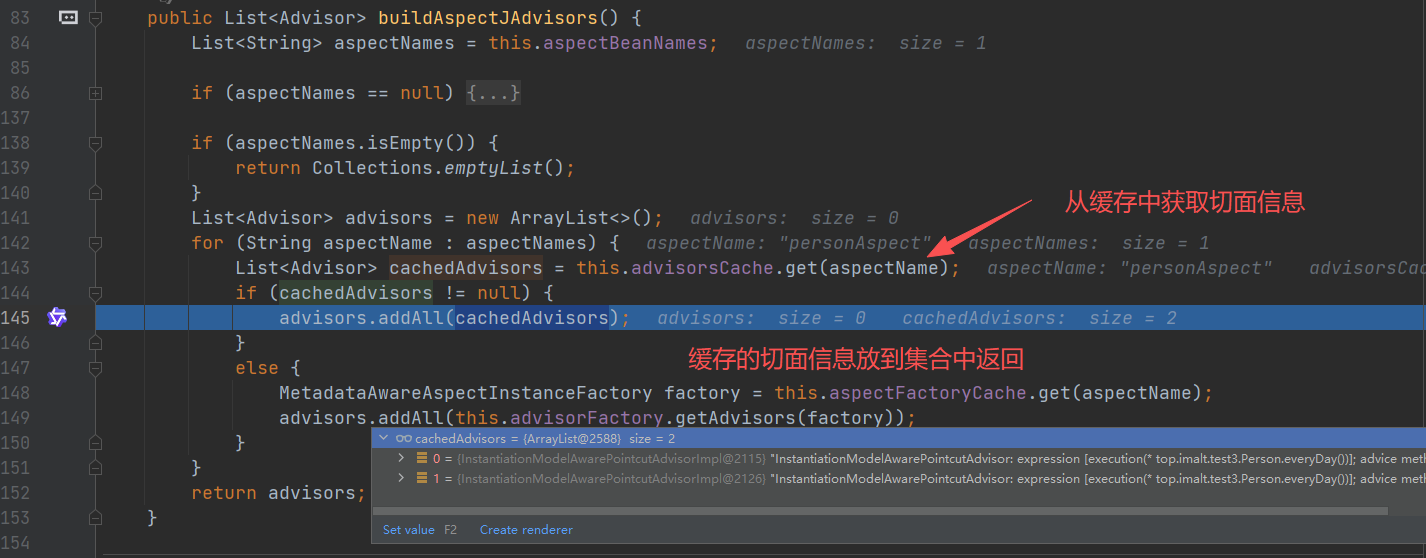
进入 buildAspectAdvisors(),这个方法就是前面将切面信息放入缓存 advisorsCache 中,现在这里就是要获取缓存。

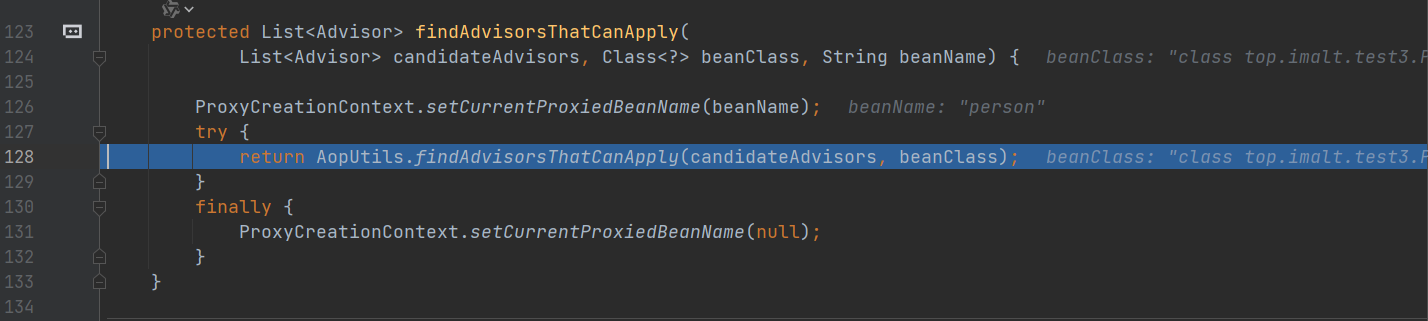
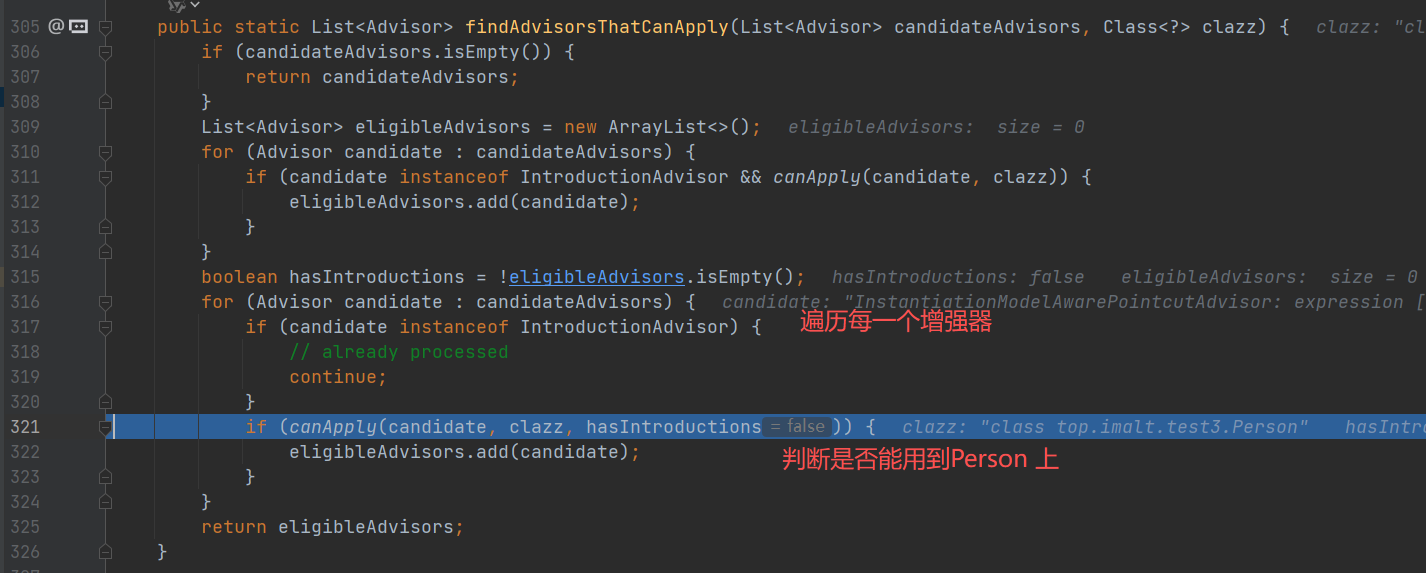
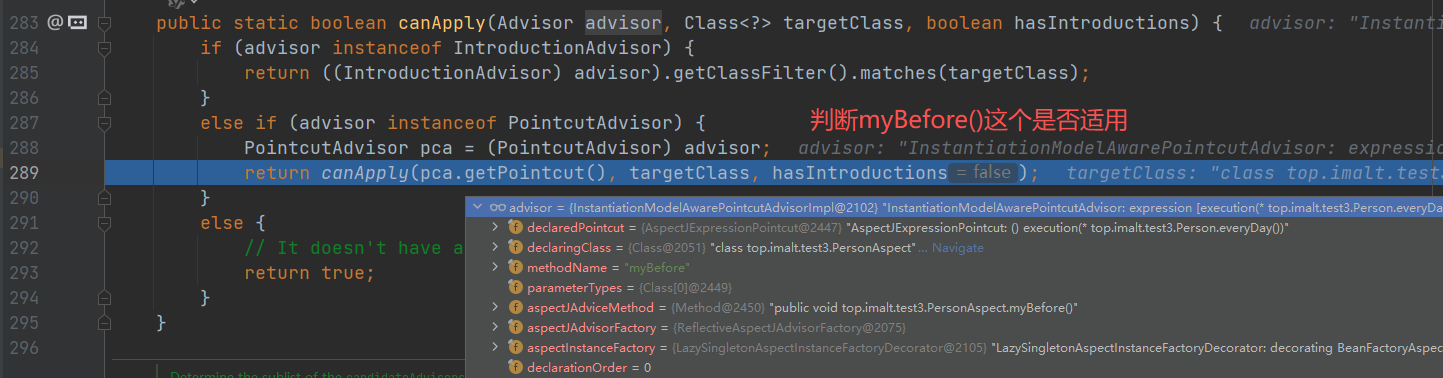
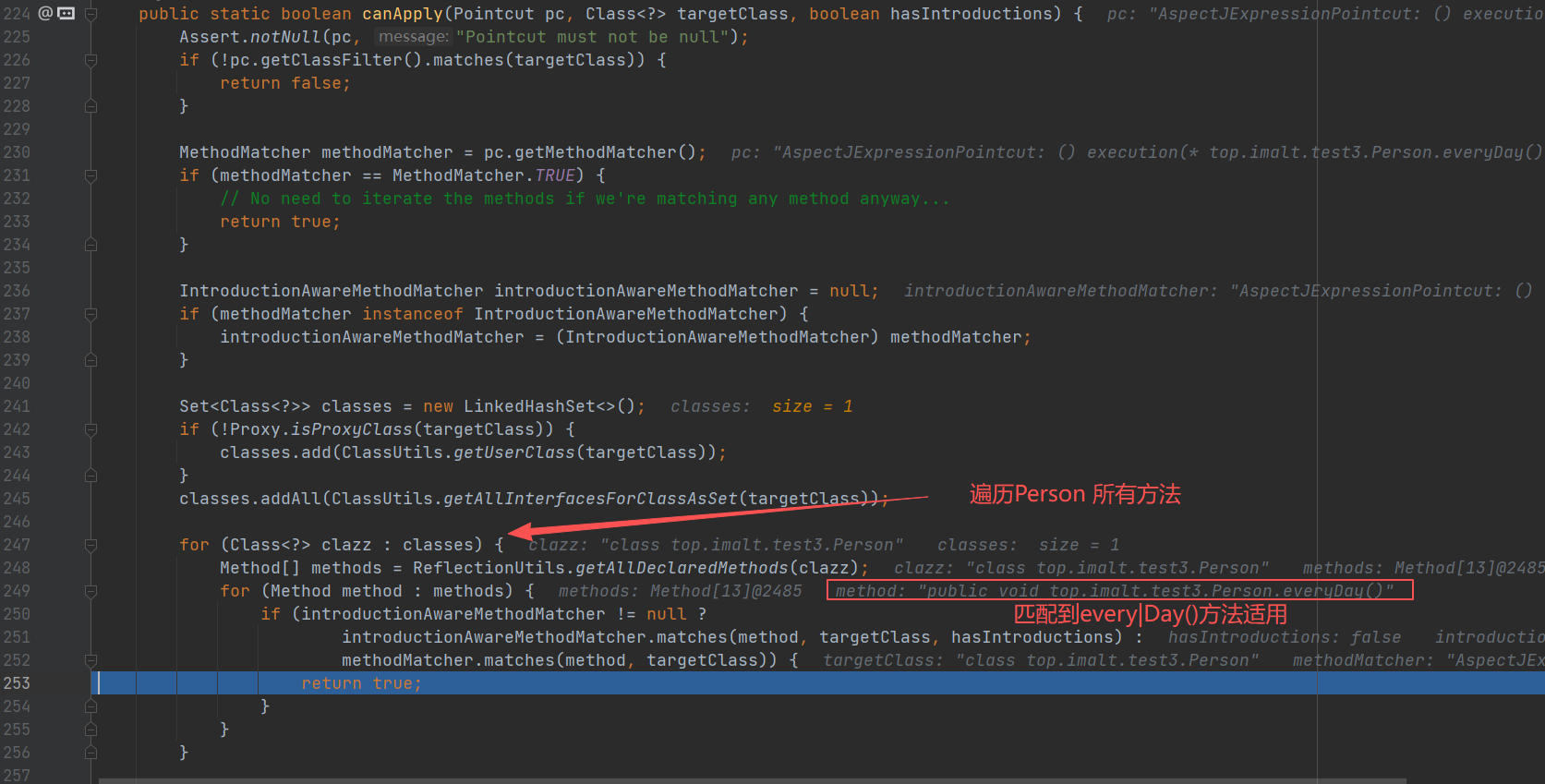
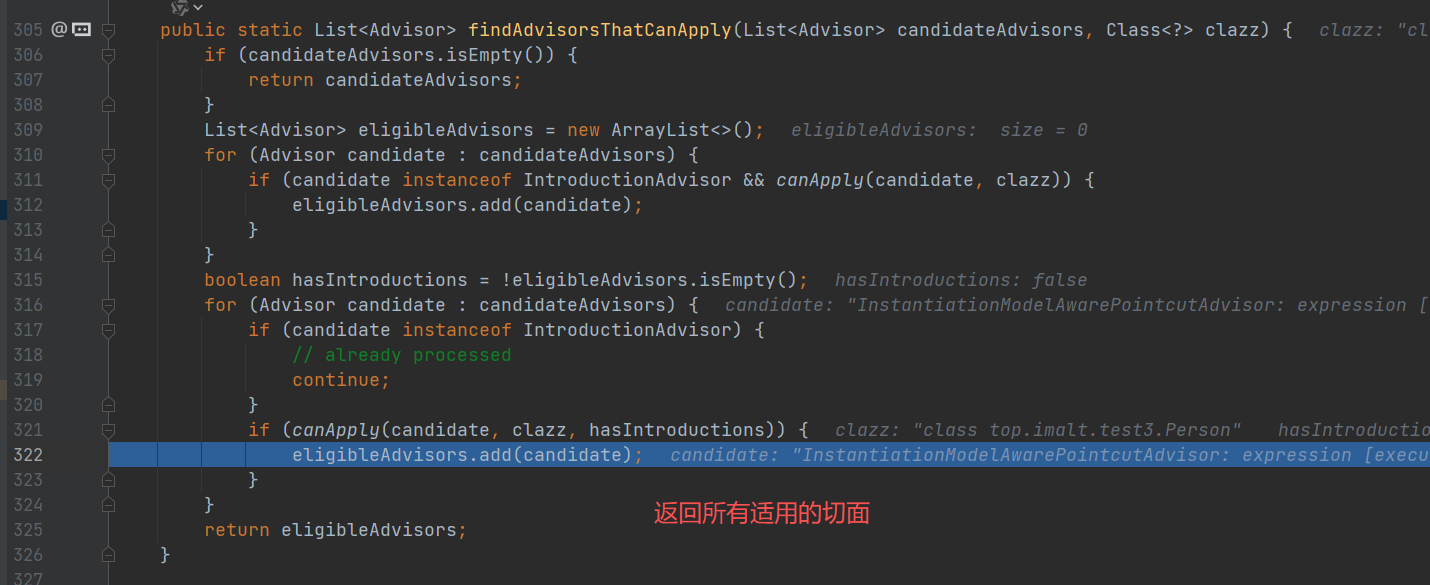
创建代理对象
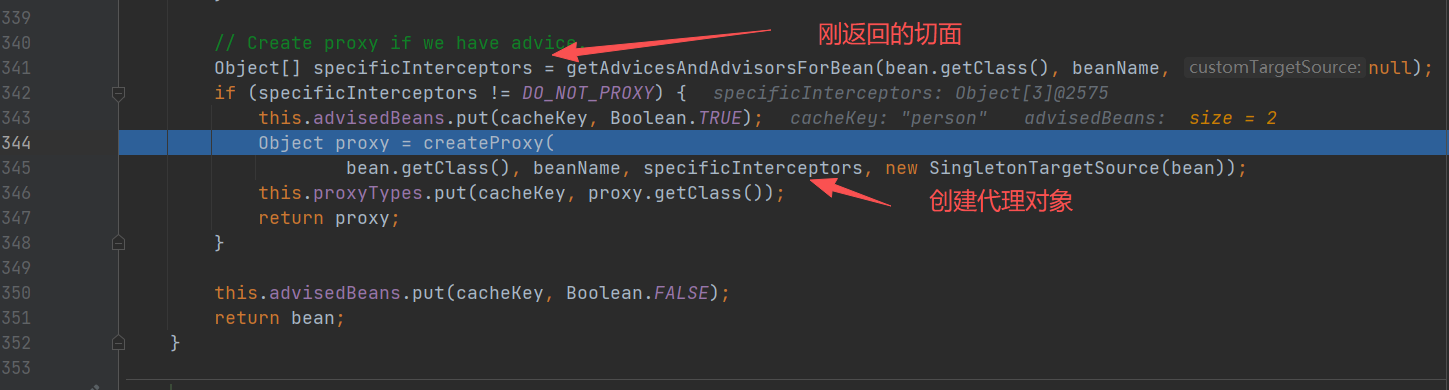
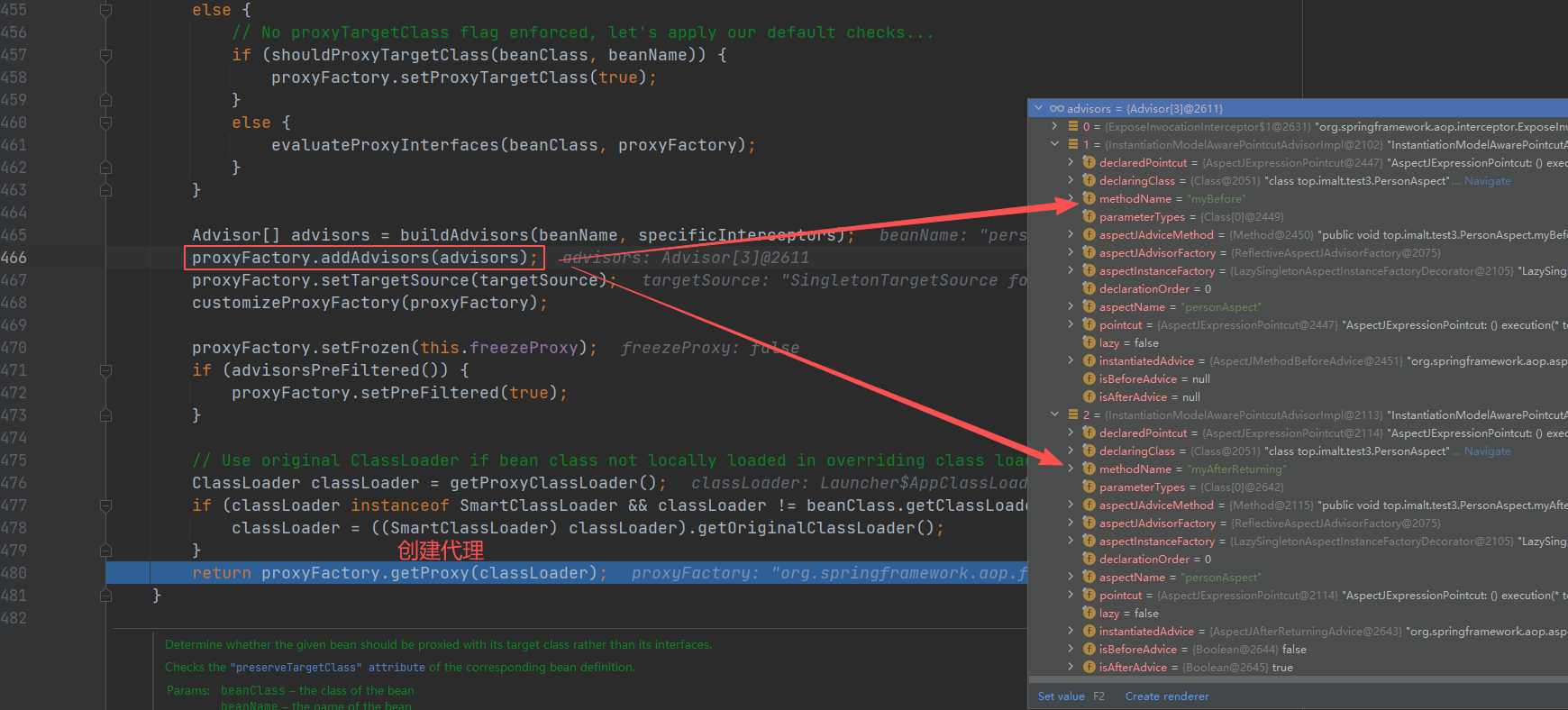


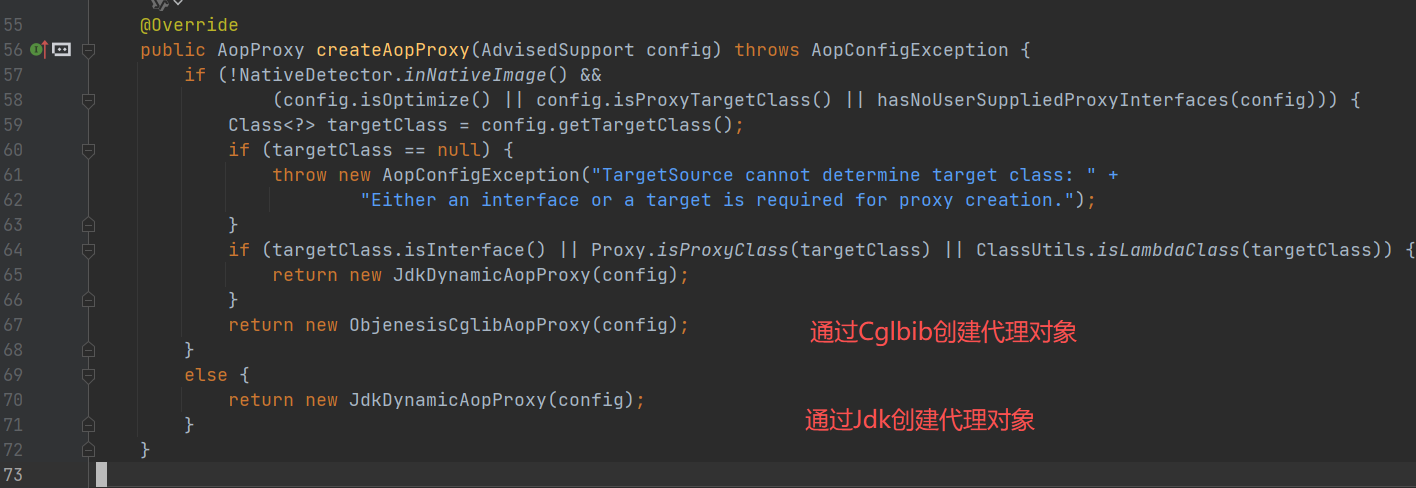
最终返回
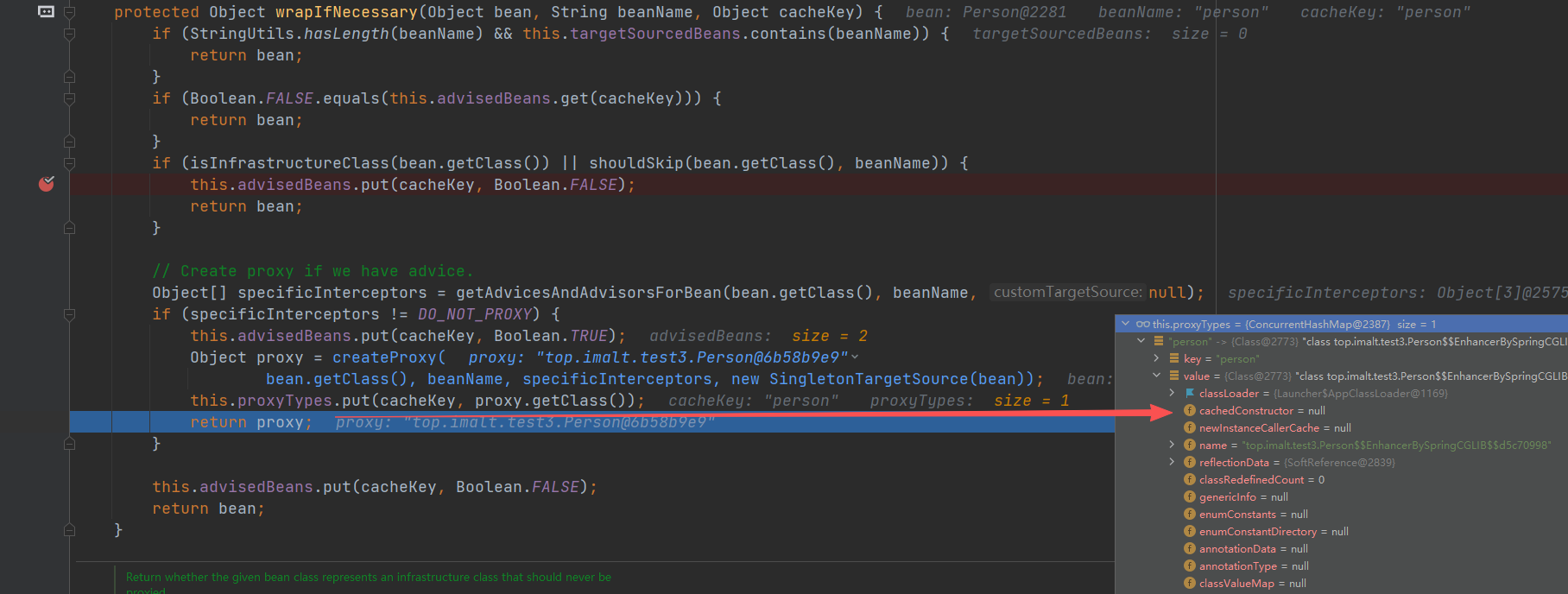
切面执行
入口:

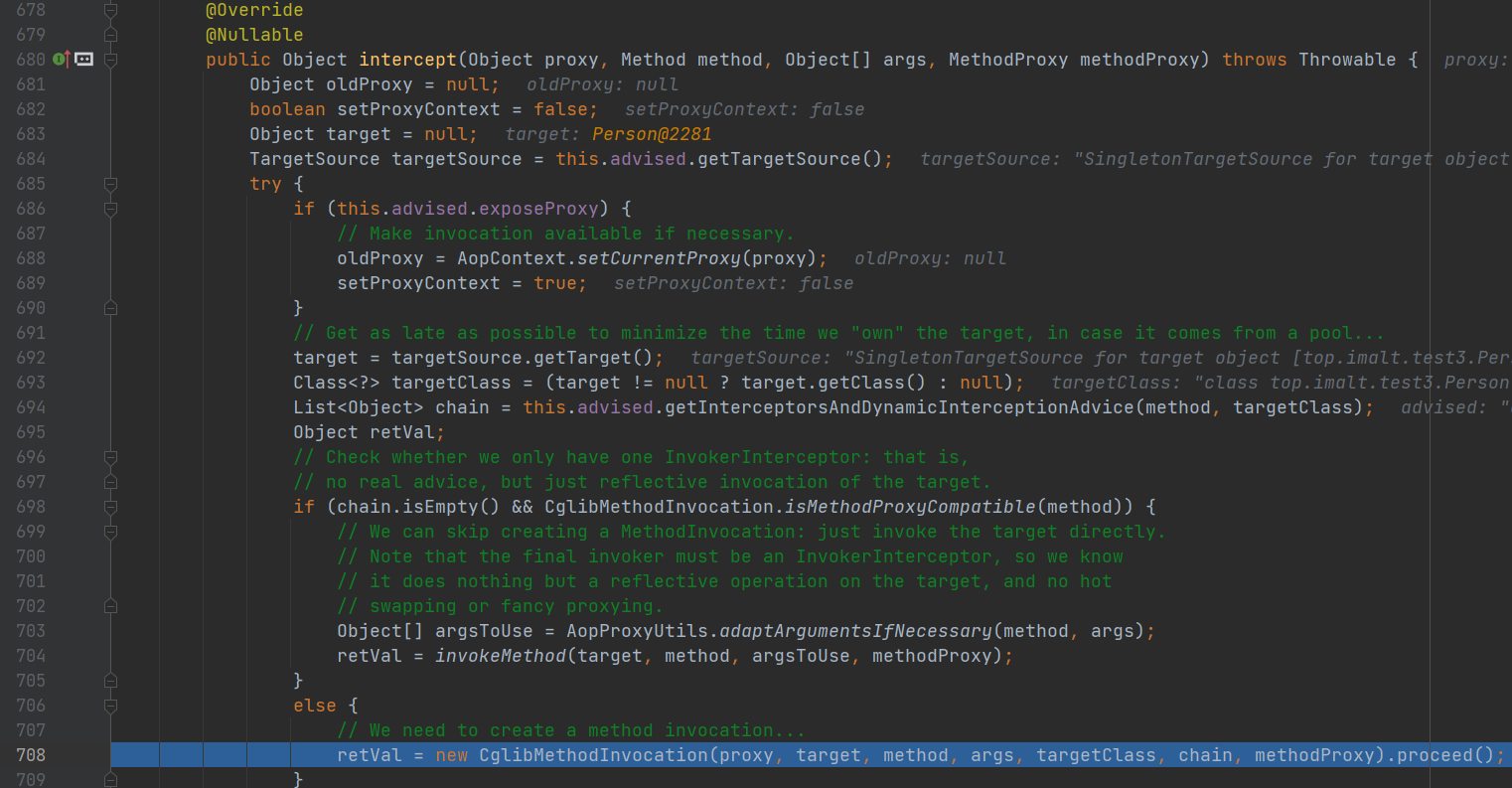
重点
- 1.设计思路:采用递归+责任链的模式;
- 2.递归:反复执行 CglibMethodInvocation的proceed();
- 3.退出递归条件:interceptorsAndDynamicMethodMatchers 数组中的对象,全部执行完毕;
- 4.责任链:示例中的责任链,是个长度为3的数组,每次取其中一个数组对象,然后去执行对象的invoke()。
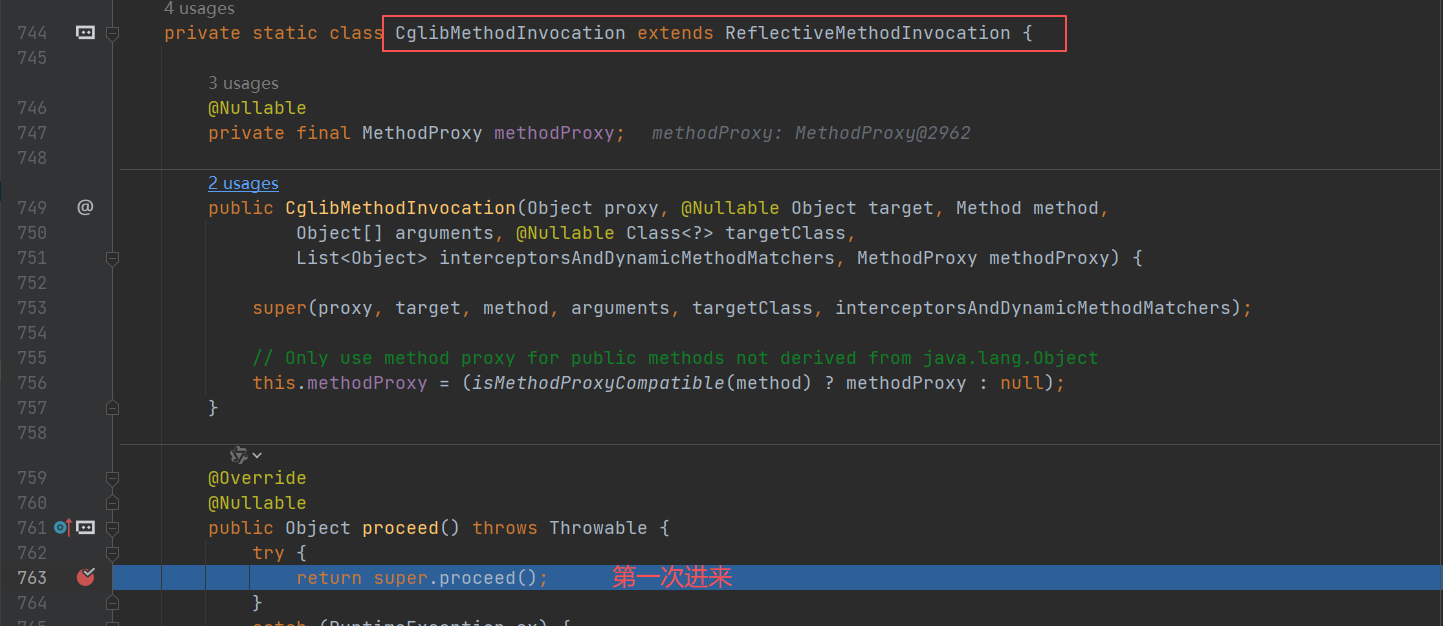
第一次递归
第一个参数是ExposeInvocationInterceptor,执行invoke() 方法,什么也没干,继续执行CglibMethodInvocation 的processd()

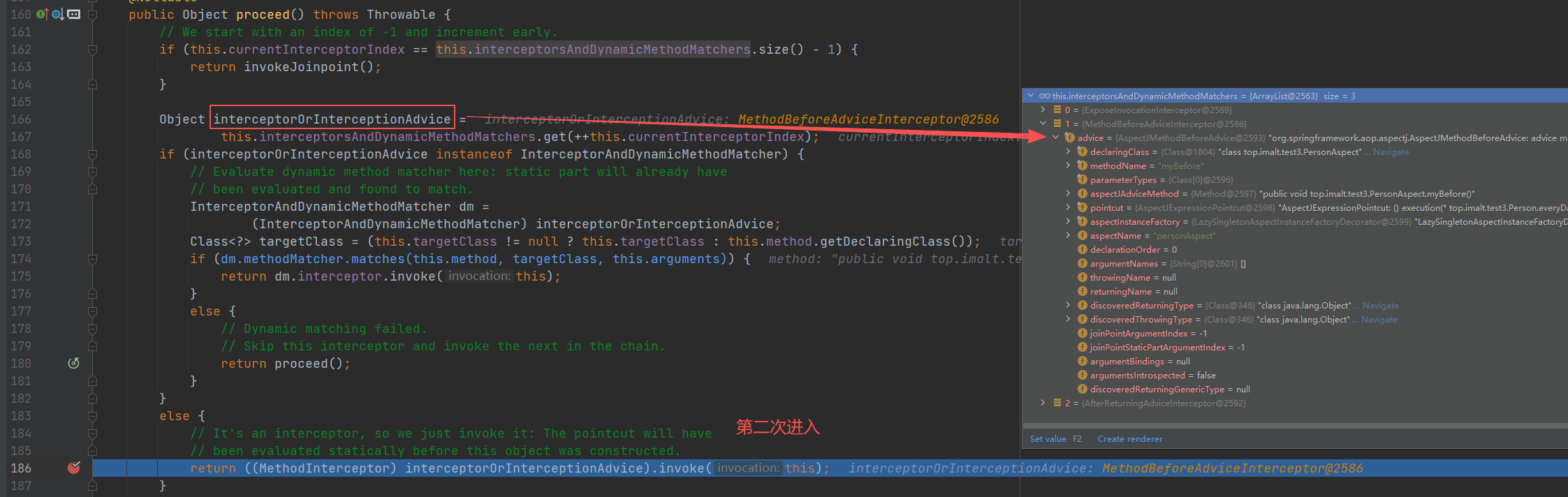
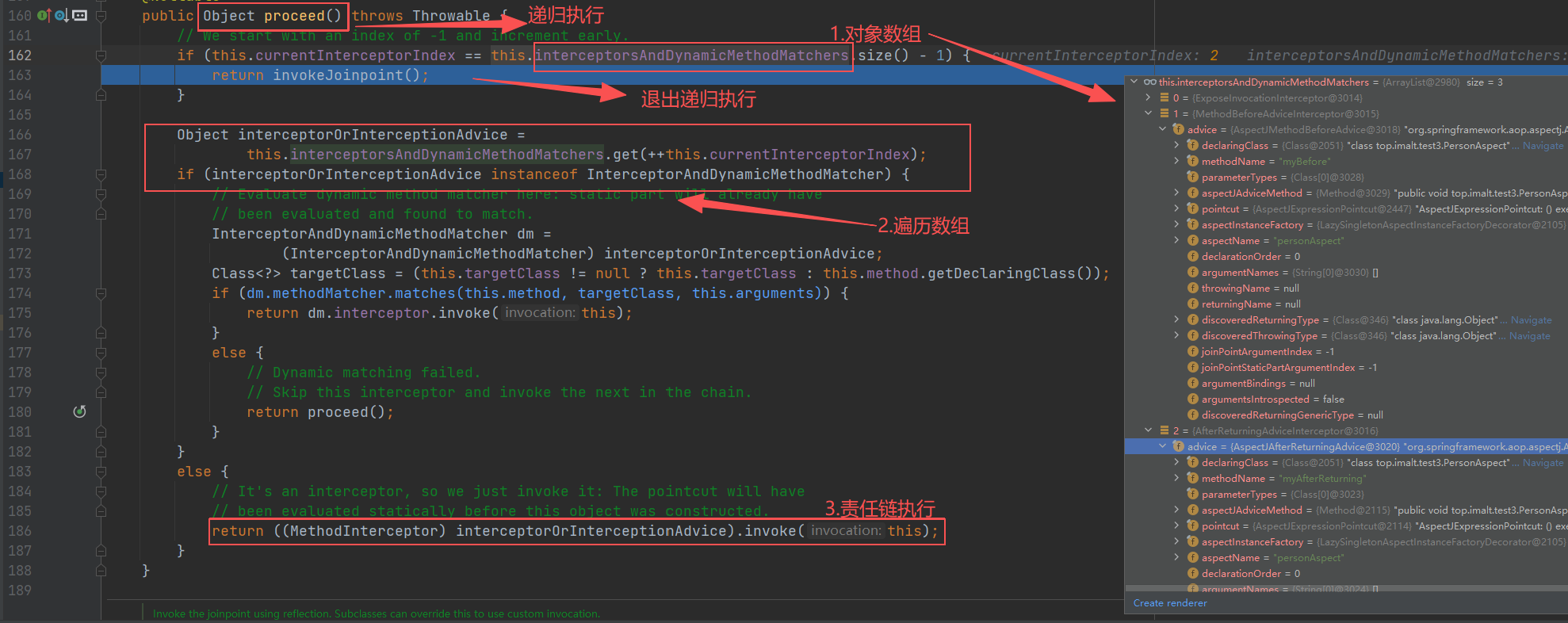
第二次递归
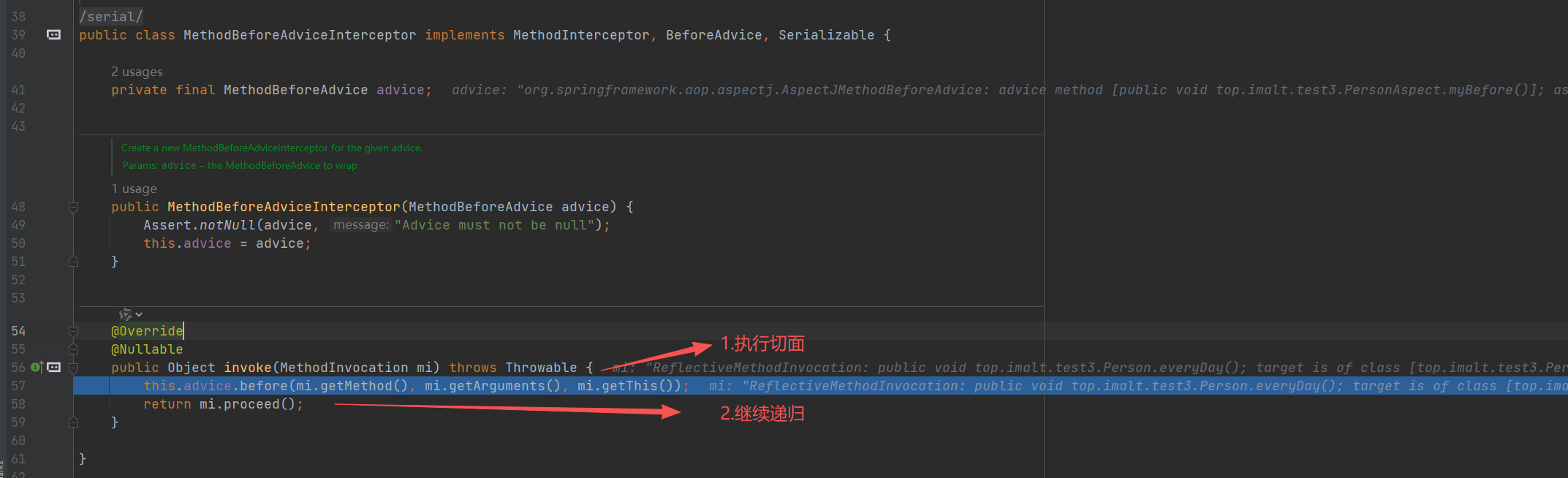
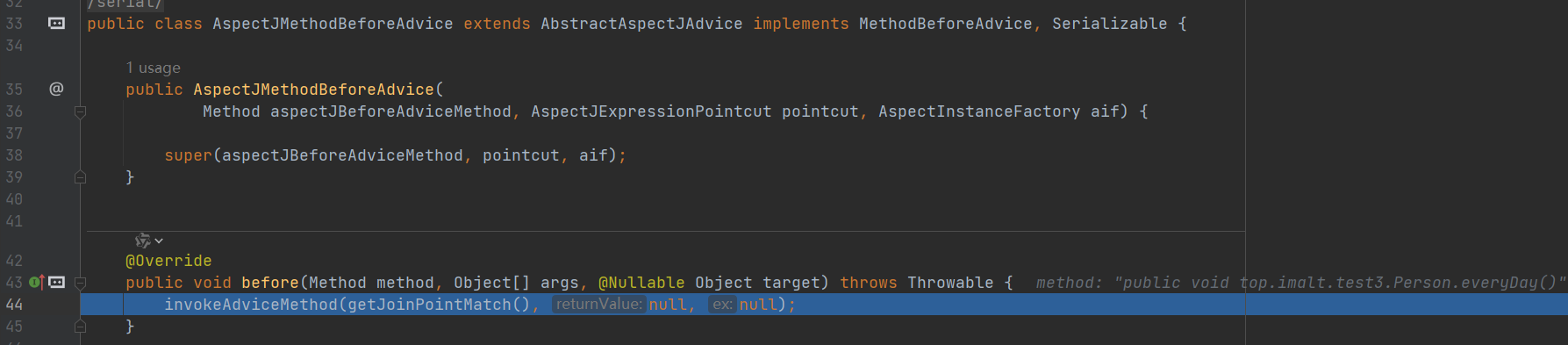



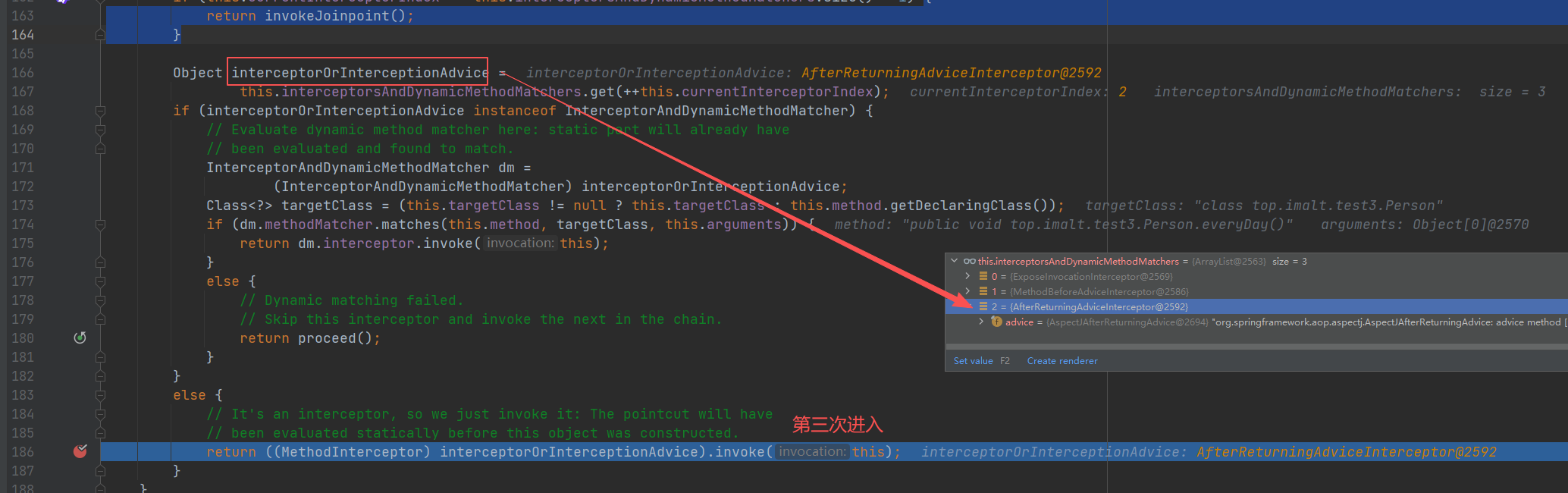
第三次递归
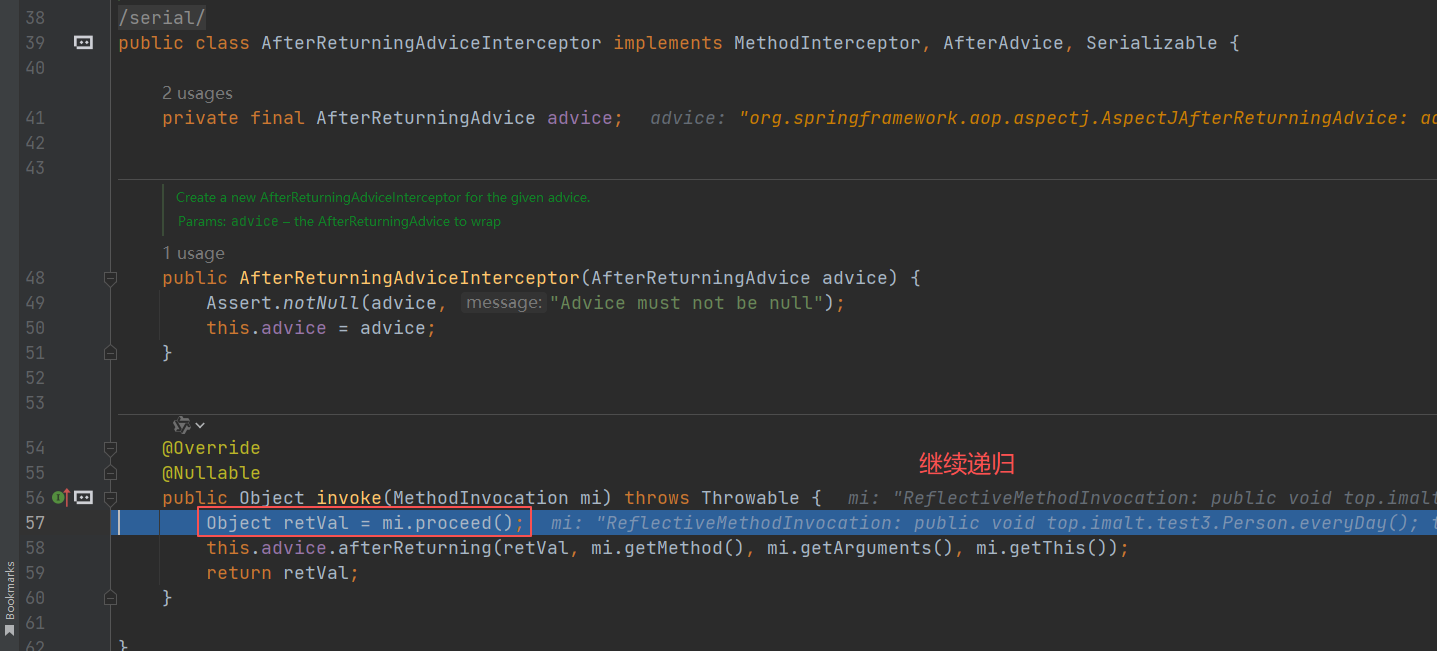
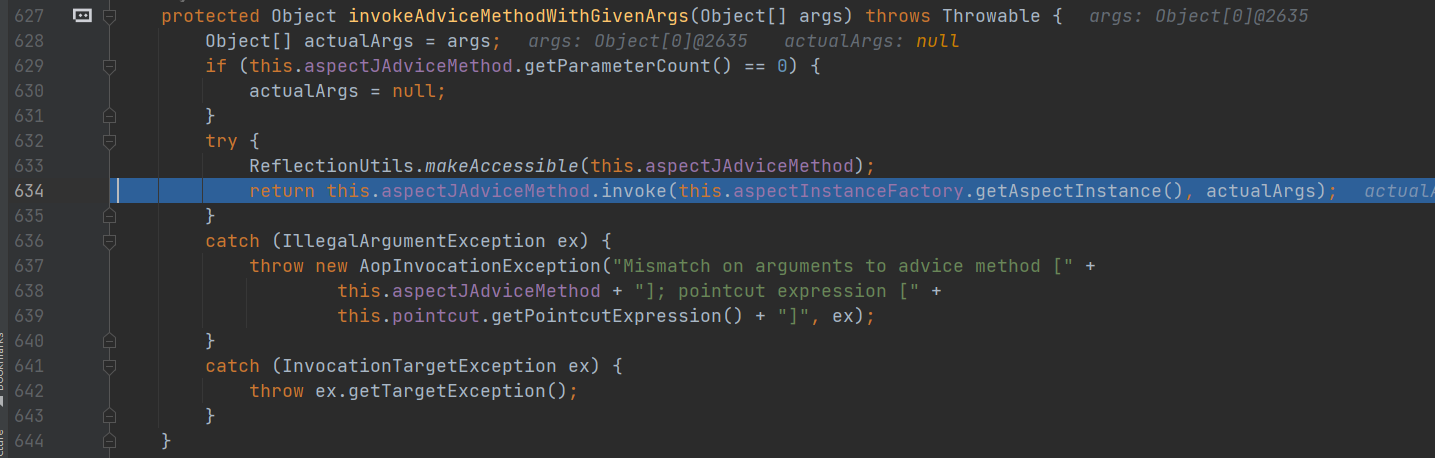
第四次进入

查看 invokeJoinpoint(),调用主方法
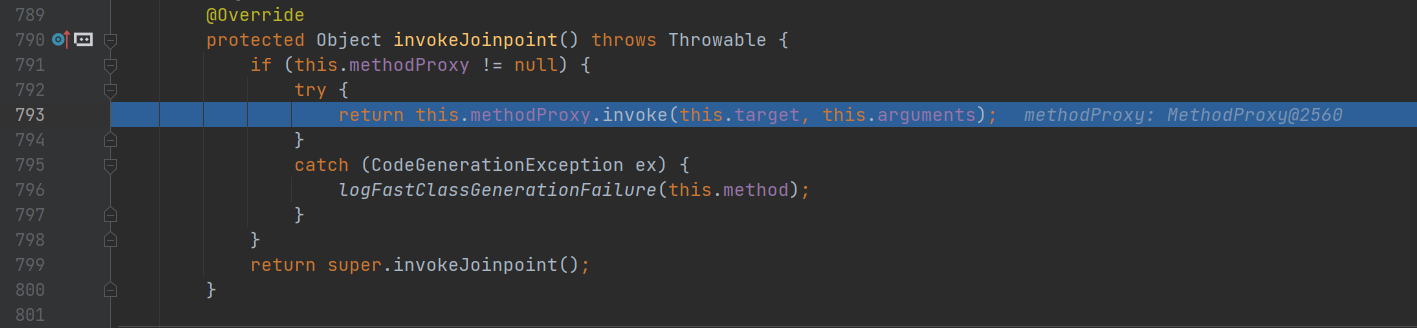
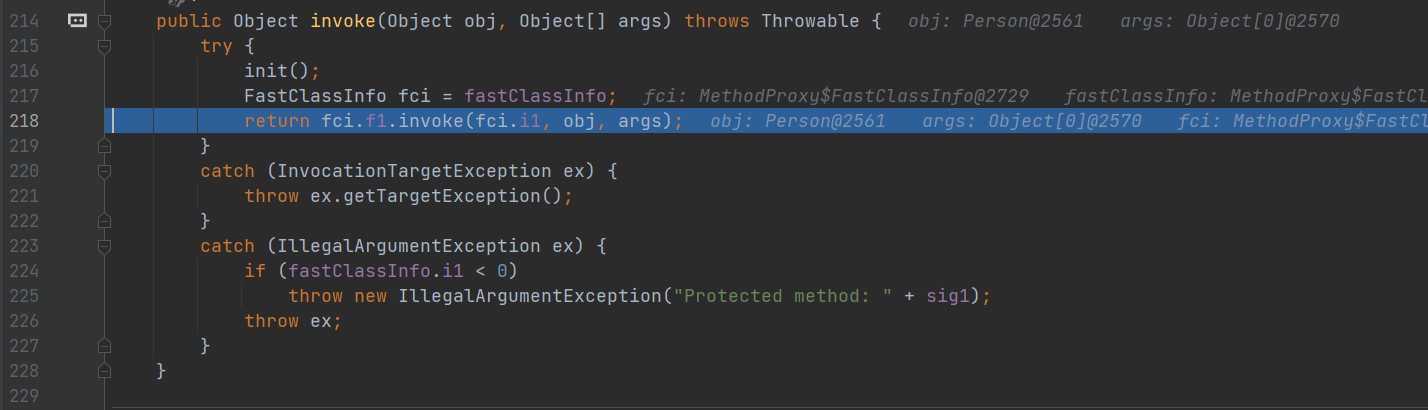

执行完毕后,回到第三次递归入口
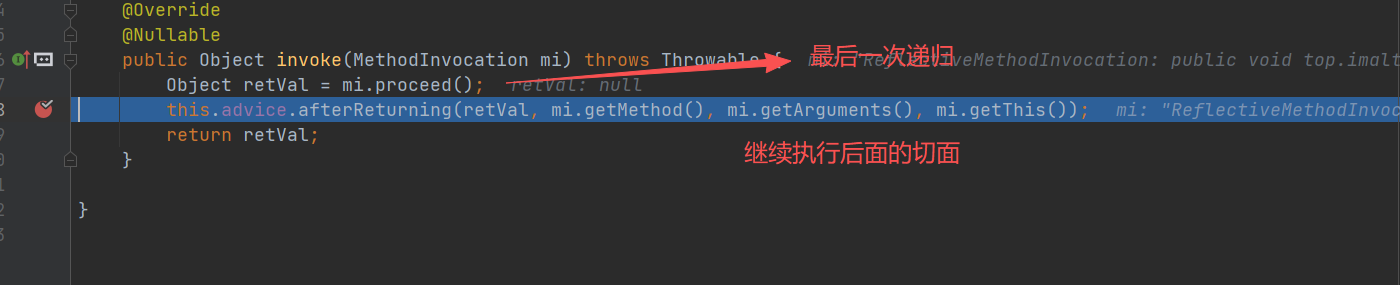


设计思路
责任链模式
- 纯粹的责任链模式,对象内部有一个自身的next 对象,执行完当前对象的方法未尾,就会启动 next 对象的执行,直到最后一个 next 对象执行完毕,或者中途因为某些条件中断执行,责任链才会退出。
- 这里 CglibMethodlnvocation 对象内部没有 next 对象,全程是通过 interceptorsAndDynamicMethodMatchers长度为3的数组控制,依次去执行数组中的对象,直到最后一个对象执行完毕,责任链才会退出。
- 这个也属于责任链,只是实现⽅不⼀样
类之间管理
1 | // 入口 |
主对象是 CglibMethodInvocation,继承于 ReflectiveMethodlnvocation,然后process()的核心逻辑,核心都在ReflectiveMethodInvocation 中.
ReflectiveMethodInvocation 中的 process()控制整个责任链的执行
process()方法,里面有个长度为 3的数组interceptorsAndDynamicMethodMatchers,里面存储了3个对象,分别为 ExposelnvocationInterceptor、MethodBeforeAdviceInterceptor、 AfterReturningAdvicelnterceptor
3个对象都集成了MethodInterceptor接口
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15public interface MethodInterceptor extends Interceptor {
/**
* Implement this method to perform extra treatments before and
* after the invocation. Polite implementations would certainly
* like to invoke {@link Joinpoint#proceed()}.
* @param invocation the method invocation joinpoint
* @return the result of the call to {@link Joinpoint#proceed()};
* might be intercepted by the interceptor
* @throws Throwable if the interceptors or the target object
* throws an exception
*/
Object invoke( MethodInvocation invocation) throws Throwable;
}每次执行invoke()方法时,都会执行CglibMethodInvocation 的process()方法,核心原理:
- 接口继承:数组中的3个对象,都是继承Methodlnterceptor 接口,实现里面的invoke()方法;
- 类继承:我们的主对象 CglibMethodinvocation,继承于 RefectiveMethodlnvocation,复用它的 process(
方法; - 两者结合(策略模式):invoke()的入参,就是 CglibMethodlnvocation,执行invoke() 时,内部会执行CglibMethodInvocation.process(),这个其实就是个策略模式。
